Nunca se miente tanto como antes de las elecciones, durante la guerra y después de la cacería.
Otto Von Bismarck.
Por Macario Hernández Garza.
Seminario: Las encuestas electorales: la experiencia de 2012
Los días 22 y 23 de noviembre de 2012 se llevó a cabo en el auditorio del Instituto Federal Electoral (IFE) el seminario Las encuestas electorales: la experiencia de 2012. Este seminario fue organizado por el IFE, la Asociación Mexicana de Agencias de Inteligencia de Mercado y Opinión A.C. (AMAI), World Association for Public Opinion Research (WAPOR) y el Centro de Investigadores de la Opinión Pública.
En este seminario hubo seis mesas de discusión y 24 ponentes. En la Tabla 1 expongo los argumentos o excusas más típicas de algunos de los defensores de sí mismos, por las exageradas discrepancias entre las estimaciones de los encuestadores y los resultados oficiales de los candidatos. Los ponentes tratan de achacar a otras causas, lo que en realidad fue una simple y llana manipulación de las estimaciones de las encuestas por los propios encuestadores.
Porque no debemos de desviar la atención, está en duda el trabajo y la honorabilidad de los encuestadores, no la capacidad de las encuestas como una metodología estadística capaz de pronosticar las preferencias electorales de los candidatos.
Las encuestas son fotografías del momento, no pronostican. (Reforma, Demotecnia e Ipsos-Bimsa si pronosticaron ¿es esto una anomalía?)
Raúl Trejo Delarbre afirma que las encuestas son radiografías del momento en que se miden, no anticipan el futuro. Esto es análogo a la metáfora de la foto: las estimaciones son una foto del momento en que se realizan.
Estoy de acuerdo con Trejo Delarbre en que las estimaciones de una encuesta son una foto del momento, además, esta medición o foto instantánea tiene asociada –o debería tener según la metodología reportada por los encuestadores- un error aleatorio. Y como he escrito en un anterior artículo, el cual puede consultarse dando clic en la siguiente liga, este error tiene una distribución Normal. Ahí se mencionaban tres principios que deben satisfacer una estimación procedente de una encuesta probabilística:
- Las desviaciones de las estimaciones respecto de la preferencia electoral tienen la misma probabilidad de ser tanto positivas como negativas, es decir, las estimaciones pueden ser mayores que la preferencia electoral, o menores que ésta con la misma probabilidad.
- Es más probable observar desviaciones pequeñas que desviaciones grandes.
- Las estimaciones tienen una distribución normal.
El asunto es que Trejo Delarbre usa la metáfora de la estimación de una encuesta como una foto para tratar de justificar los resultados discrepantes de la mayoría de los encuestadores con el resultado oficial de los candidatos.
En algún momento de su ponencia Trejo Delarbre afirma, con más vehemencia que fundamento, “lo que pasa es que se les olvida, incluso a algunos encuestadores, que las encuestas son diagnóstico no pronóstico”. Raúl Trejo Delarbre repite sus argumentos como mantras, o un atractivo eslogan, pero no los acompaña con datos que los respalden.
Las películas de Gea-Isa e Indermerc- Harris cuentan historias radicalmente distintas a la de Demotecnia.
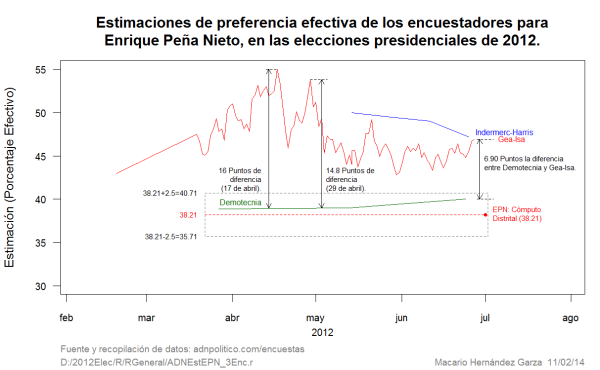
Figura 1
Si las estimaciones son fotos, podemos decir que el conjunto de estimaciones para un candidato nos da una película de cómo se comportó la preferencia electoral del candidato. En la Figura 1 se puede apreciar que las películas contadas por las estimaciones de Gea-Isa e Indermerc-Harris son radicalmente distintas a la de Demotecnia. Hay un momento donde la diferencia entre las estimaciones de Gea-Isa y Demotecnia es de 16 puntos, en otra ocasión es de 14.8 puntos. Gea-Isa dijo realizar 102 encuestas y, desde un punto de vista estadístico, su desempeño fue desastroso. A Demotecnia le bastaron tres encuestas para tener un buen desempeño. El rango de variabilidad de las estimaciones de Gea-Isa fue de 12.2 puntos, el de Demotecnia fue de sólo 1.3 puntos, casi una décima parte del rango de Gea-Isa. En la Figura 1 también se puede ver que el desempeño de Indermerc-Harris es peor todavía que el de Gea-Isa.
Los argumentos 2, 9, 14 y 16, son prácticamente equivalentes al argumento de que la estimación de la preferencia electoral de un candidato es una foto del momento. La pregunta es ¿Por qué al hacer una película, uniendo las fotos, las historias de estas películas son tan diferentes? Desde mi punto de vista, es debido a la manipulación de las estimaciones de las encuestas.
Javier Alagón afirma que: hubo ocultamiento de la intención del voto; los sesgos de las respuestas son complejos; problemas con la asignación de indecisos. Además de los argumentos de Javier Alagón, del argumento de que las encuestas no pronostican y los restantes de la Tabla 1, que tratan de explicar los resultados desastrosos de la mayor parte de los encuestadores. La pregunta clave es: ¿Por qué estos problemas no afectaron a los encuestadores que si pronosticaron correctamente? Demotecnia, Reforma e Ipsos-Bimsa fueron las únicas casas encuestadoras cuyas tres estimaciones para Peña Nieto, López Obrador y Vázquez Mota estuvieron dentro de precisión, es decir, sus tres estimaciones pronosticaron estadísticamente los resultados de estos tres candidatos. Entonces señores encuestadores, en qué quedamos ¿pronostican o no las encuestas?
Es erróneo medir el éxito de las encuestas comparándolas con los resultados electorales (sic y recontra sic).
Trejo Delarbre y Ulises Beltrán de BGC se atreven a afirmar que: es erróneo medir el éxito de las encuestas comparándolo con los resultados electorales. Entonces, ¿cómo pensarán medir estos señores el desempeño de las estimaciones de las encuestas? Sería como afirmar que es erróneo medir el éxito de la actuación de un tirador con arco por la proximidad de sus impactos en relación al centro del blanco ¡Un absurdo total!
Las razones de Berumen
Edmundo Berumen le achaca el mal desempeño de la mayor parte de los encuestadores a “la no-respuesta total creciente que toda encuesta está experimentando debido a la inseguridad” y “a las dificultades que la inseguridad ocasiona en el trabajo de campo”. Sin embargo, la situación es que estos factores no afectaron a Reforma, Demotecnia e Ipsos-Bimsa para tener un buen desempeño, es decir, sus estimaciones finales estuvieron dentro de precisión y, por tanto, predijeron con éxito el resultado principal de los tres principales candidatos.
En la Figura 2, se puede advertir como Demotecnia con sólo tres encuestas, tuvo un mejor desempeño que Gea-Isa con 102 encuestas que dijo realizar. Las dos curvas trazadas por las estimaciones de estas dos casas encuestadoras nos cuentan historias muy diferentes en relación a las preferencias electorales de López Obrador. Se puede ver en estas curvas, cómo en algunos momentos, la diferencia entre las estimaciones de Gea-Isa y Demotecnia fueron mayores a diez puntos porcentuales, lo que delata la manipulación de las estimaciones de Gea-Isa que están, sistemáticamente, por debajo de las estimaciones de Demotecnia en todo momento.
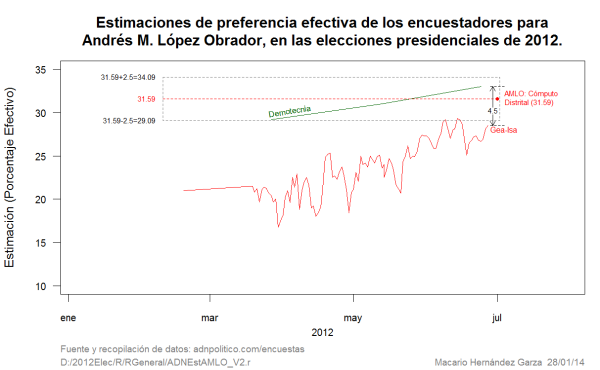
Figura 2
En la Figura 3 se puede apreciar que Covarrubias, con sólo cinco encuestas, en el caso de Josefina Vázquez Mota tuvo un mejor desempeño que Gea-Isa con las 102 encuestas que dijo realizar (tengo mis dudas de que lo haya hecho ¿para qué llevar a cabo tantas encuestas si al final las van a manipular?). Además, según las estimaciones de Covarrubias, la preferencia electoral de Vázquez Mota tuvo menos fluctuaciones y variabilidad de la que nos quiso hacer creer Gea-Isa y otras casas encuestadoras.
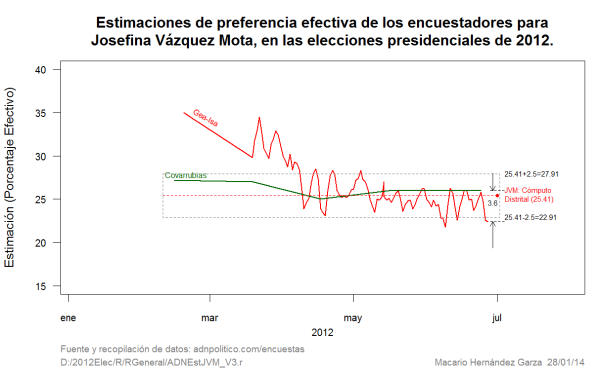
Figura 3
¿Excepcional “suerte” de Peña Nieto o parcialidad de las casas encuestadoras?
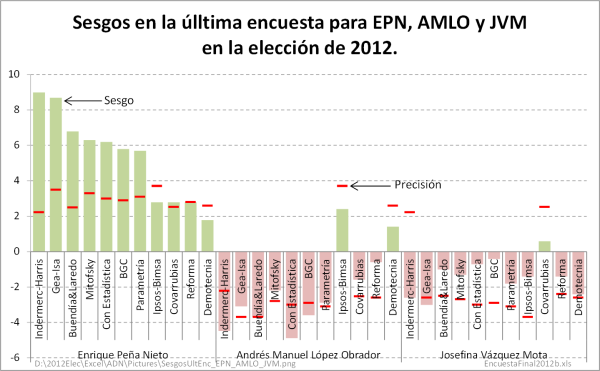
Figura 4
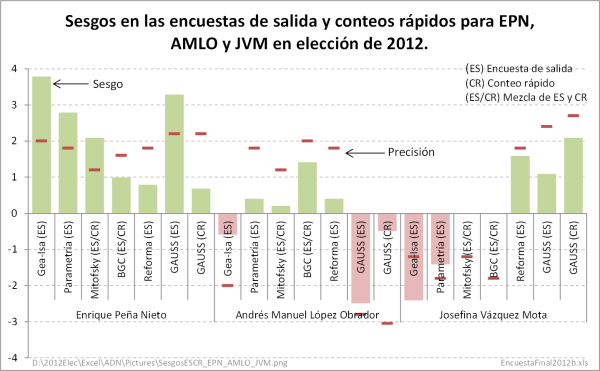
Figura 5
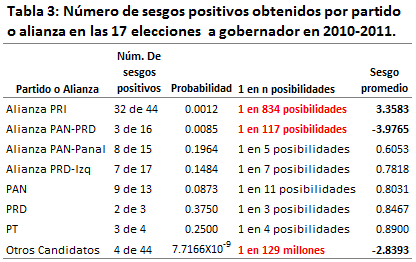
Enrique Peña Nieto tuvo 11 sesgos positivos en la última encuesta de 11 encuestadores participantes (11 sesgos positivos de 11). Asimismo tuvo 7 sesgos positivos en las encuestas de salida y conteos rápidos (7 sesgos positivos de 7). Peña Nieto tuvo entonces, sesgos positivos zapato, es decir, 18 sesgos positivos de 18. La probabilidad de que ocurra este evento en encuestas imparciales es 3.8147×10-6. Una posibilidad en 262,144.
Debemos recordar que los sesgos de las estimaciones de un candidato tienen la misma probabilidad de ser positivos o negativos. La facilidad con la que ocurren estos eventos muy improbables es, simplemente, por la parcialidad de los encuestadores. El asunto no es que ocurran eventos muy poco probables, la cuestión es que ocurren con demasiada frecuencia, y siempre para beneficiar al candidato “políticamente correcto”.
Se puede advertir en los dos gráficos anteriores que Peña Nieto es el único candidato que tuvo estimaciones fuera de precisión y beneficiándolo. Por el contrario, las únicas estimaciones fuera precisión de los encuestadores para López Obrador y Vázquez Mota fueron para perjudicarlos.
Pudiera ser que:
- a) Enrique Peña Nieto sea un tipo con una suerte difícil de ver en otro mexicano. Un auténtico «elegido de los dioses».
- b) Que México se encuentre en una región bizarra del universo donde el azar beneficia únicamente a un candidato.
- c) Que la mayoría de las casas encuestadores son parciales.
¿Usted qué piensa? estimado lector.
Algunos índices de desempeño de las casas encuestadoras
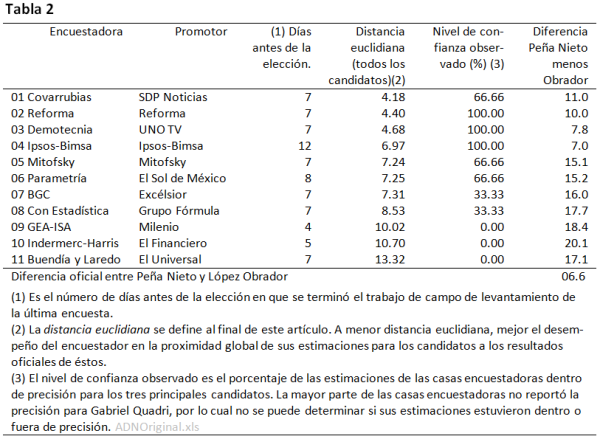
En la Tabla 2, se muestran los once encuestadores, sus patrocinadores declarados, el número de días antes de la elección en que dijeron terminar su trabajo de campo, y tres índices de desempeño de su última estimación: la distancia euclidiana (distancia global de las últimas estimaciones del encuestador a los resultados oficiales de los candidatos), el nivel de confianza observado y la diferencia de las estimaciones del encuestador para Peña Nieto y López Obrador.
A contrapelo de las opiniones de los encuestadores que afirman que las encuestas no predicen, se puede observar de la Tabla 2 que las primeras cuatro casas encuestadoras tuvieron una actuación aceptable, considerando su última estimación. Covarrubias tuvo la distancia euclidiana más pequeña (distancia global), además, tuvo dos de sus tres estimaciones dentro de precisión (66% de nivel de confianza observada). Reforma, Demotecnia e Ipsos-Bimsa tuvieron la segunda, tercera y cuarta distancias euclidianas más pequeñas y además tuvieron a las tres estimaciones dentro de precisión (nivel de confianza observada del 100%) para los tres principales candidatos.
Otros argumentos de Raúl Trejo Delarbre
Raúl Trejo Delarbre, en su intervención en la Mesa 3 del Seminario de Análisis antes referido, también señala que las estimaciones de las casas encuestadoras, muy discrepantes de los resultados oficiales de los candidatos, se deben a la prohibición a publicar resultados electorales tres días antes de las elecciones federales que marca el artículo 237 de Cofipe. Y que con ello hay un ayuno de información discriminatoria ya que los partidos e instituciones si pueden conocer las encuestas. Trejo Delarbre también afirma que con la anterior disposición del Cofipe se vulnera el derecho de los ciudadanos a estar bien informados.
Es evidente que las encuestas son pronósticos de corto plazo, entre mayor tiempo tratemos de extrapolar el pronóstico mayor incertidumbre o menos probabilidad habrá de que se cumpla éste. Los hechos comprobaron, al menos en la elección de 2012, que la anterior restricción del Cofipe no fue crítica. Si se observa la Tabla 2, Ipsos-Bimsa fue la encuestadora que terminó su trabajo de campo más alejado del día de la elección (12 días) y fue una de las tres casas encuestadoras que pronóstico acertadamente el resultado de los tres principales candidatos (estimaciones dentro de precisión), además de que pronosticó la diferencia más cercana entre Peña Nieto y López Obrador: 7 puntos, contra 6.6 puntos del resultado oficial.
Por el contrario, los encuestadores que terminaron su trabajo de campo más cercano al día de la elección: Indermerc-Harris (5 días) y Gea-Isa (4 días), fueron dos de las encuestadoras con peor desempeño: tuvieron sus tres estimaciones fuera de precisión y con peores proximidades globales a los resultados oficiales. Lo anterior prueba que, lo que más “afectó” a las estimaciones de las casas encuestadoras, fue la manipulación de sus propias estimaciones, antes que la proximidad del trabajo de campo a la fecha de la elección. Es decir la restricción que impone el artículo 237 del Cofipe no fue crítica, pero sí lo fue la deshonestidad de las casas encuestadoras.
La difusión de las estimaciones de las casas encuestadoras, más que información, fue propaganda, es decir, se usaron como spots propagandísticos favorables a Peña Nieto, no tenían ningún tipo de información valiosa para la ciudadanía; por tanto, buscaron inducir el voto provocando el efecto Bandwagon o “efecto arrastre” que ya hemos señalado en un artículo anterior, y que usted puede consultar dando clic en la siguiente liga. Las casas encuestadoras son las que principalmente vulneraron el derecho de la información de la ciudadanía, más que el artículo 237 del Cofipe, como lo señala Trejo Delarbre.
Trejo Delarbre afirma también que hubo una irracional condena a encuestas y a encuestadores. Sin embargo, si algo es irracional es la defensa que realiza Trejo Delarbre de las casas encuestadoras. Hemos visto en este y en anteriores artículos, que las “equivocaciones” de las casas encuestadoras, tanto en las elecciones presidenciales de 2012, como en las elecciones de gobernador en los años 2010 y 2011, tuvieron una intencionalidad para favorecer abrumadoramente a los candidatos del PRI. Esta intencionalidad no se pudo dar sin una intervención humana, es decir, sin un acuerdo entre las casas encuestadoras.
Una visión global de las estimaciones de los encuestadores
La Figura 6 nos da una visión global de la actuación de las casas encuestadoras para los tres principales candidatos. Se puede observar que la mayor parte de éstos, benefician a Peña Nieto con grandes sesgos positivos y, por el contrario, perjudican a López Obrador y a Vázquez Mota. También se puede apreciar como la actuación de Demotecnia, en el caso de Peña Nieto y López Obrador (curvas encerradas en rectángulos); y de Covarrubias, en el caso de Vázquez Mota (curva encerrada en un rectángulo), ponen en evidencia la acción de manipulación de las otras casas encuestadoras.
Raúl Trejo Delarbre, Ulises Beltrán, Javier Alagón, Roy Campos y otros ponentes nos quieren hacer creer que hay fuerzas caóticas influenciando el proceso de las encuestas, motivo por el cual estas no funcionan como pronósticos. Entonces, ¿cómo explicar que Reforma, Ipsos-Bimsa y Demotecnia hayan pronosticado acertadamente (estimaciones dentro de precisión) los resultados para los tres principales candidatos?
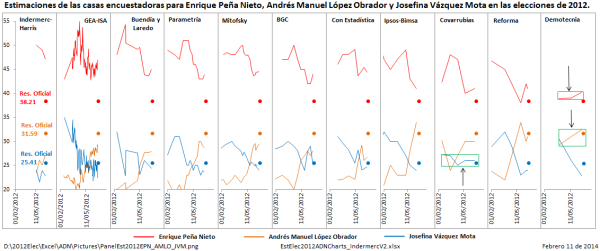
Figura 6
Todos los encuestadores estuvieron sometidos a las mismas condiciones y factores argüidos por los ponentes y resumidos en la Tabla 1. Esos factores afectaron a todos los encuestadores por igual. Reforma, Ipsos-Bimsa y Demotecnia predijeron, estadísticamente hablando, con éxito los resultados de los tres principales candidatos (estimaciones dentro de precisión). Los resultados de estas tres casas encuestadoras prueban que los resultados de las encuestas si predicen el resultado electoral y que los factores manejados por los ponentes como causantes de los grandes sesgos, no tuvieron una incidencia importante en los “malos resultados”, sino que el componente principal en esos sesgos fue la manipulación de los encuestadores de sus propias estimaciones.
¿Cómo pueden explicar que estos supuestos factores caóticos hayan actuado tanto en las elecciones a gobernador, en los años 2010 y 2011 (puede consultar un artículo anterior sobre esto en la siguiente liga), como en la elección presidencial de 2012 beneficiando en forma tan desmesurada y sistemática a los candidatos priístas? Se supone que si hay tantos y tan variados factores descontrolados deberían también beneficiar o perjudicar también en forma caótica a los diferentes candidatos.
Ahora resulta que los supuestos factores “incontrolables” actúan con una intencionalidad casi humana favoreciendo a los candidatos priístas.
No se puede decir que los encuestadores fallaron, más bien, éstos renunciaron a pronosticar los resultados de los candidatos, por favorecer a Enrique Peña Nieto. Obviamente, los puntos porcentuales que le otorgaron en exceso a Peña Nieto, los tomaron de los restantes candidatos. Por lo visto, el negocio no está en pronosticar, sino en favorecer a un candidato determinado.
Lo que se percibe es que este seminario se realizó para tratar de justificar lo injustificable: la actuación concertada de la mayoría de los encuestadores para beneficiar a Enrique Peña Nieto (EPN). Extrañamente, también los medios de comunicación dominantes como Televisa, TV Azteca, Multimedios, Milenio, etcétera favorecieron al mismo candidato EPN. Qué extraño es el azar en México cuando tanto los encuestadores como los medios de comunicación tradicionales se “equivocaron” a favor de EPN. Qué extraño que las “equivocaciones” sean políticamente correctas. Qué extraño que éstos se hayan “equivocado” a favor del candidato acusado de comprar el voto con los monederos electrónicos Monex y las tarjetas Soriana.
De nuevo, un especial agradecimiento a Daniel González Sepúlveda, por la revisión y corrección de este escrito, así como por sus aportaciones al mismo.
ANEXO: La distancia Euclidiana.
La distancia euclidiana es un indicador clave de desempeño de los encuestadores, el cual nos proporciona una medida global de la proximidad de las estimaciones de un encuestador más cercanas a la fecha de la elección, a los resultados oficiales de los candidatos.
La distancia euclidiana entre las estimaciones de una casa encuestadora a los diferentes candidatos a los resultados oficiales se calcula de la siguiente forma:
![]()
Dónde:
n: Es el número de candidatos.
Est i: Es la estimación de la casa encuestadora para el candidato i. Donde se consideran cuatro candidatos: Enrique Peña Nieto, Andrés Manuel López Obrador, Josefina Vázquez Mota, Gabriel Quadri y Otros Candidatos.
Res. Oficial i: Es el resultado oficial para el candidato i.
Trataré de ilustrarlo con un ejemplo:
Se tiene que GEA-ISA en su última encuesta, reportada en junio de 2012, las estimaciones efectiva de votantes para los candidatos fueron: Enrique Peña Nieto: 46.9, Andrés Manuel López Obrador: 28.5, Josefina Vázquez Mota: 22.40, Gabriel Quadri: 2.20, Otros: 0.
Los resultados oficiales del cómputo distrital para los candidatos fue: Enrique Peña Nieto: 38.21, Andrés Manuel López Obrador: 31.59, Josefina Vázquez Mota: 25.41, Gabriel Quadri: 2.29, Otros: 2.51.
Entonces la distancia euclidiana para las estimaciones de GEA-ISA y los candidatos en la elección presidencial de 2012, sería:
Distancia Euclidiana de las estimaciones de GEA-ISA a los resultados oficiales de los candidatos =
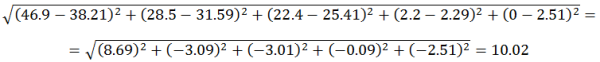
Por Macario Hernández Garza.
Me desviaré un poco de la línea que he venido siguiendo en esta serie de escritos. Creo que este desvío vale la pena. Se podrá ver que la actuación de las casas encuestadoras en las elecciones a gobernador en 2010 y 2011, fue una calca de lo que sería su actuación en la elección presidencial de 2012: el sesgo abrumador favorable a los candidatos del PRI o sus alianzas. Así que, de alguna forma, estas elecciones estatales fueron un laboratorio para las elecciones presidenciales de 2012.
Leo Zuckermann (LZ) escribió el artículo ¿Quién es quién en las encuestas?, el cual apareció en la revista Nexos de marzo de 2012. En este artículo LZ hace un análisis del desempeño de las casas encuestadoras, en 17 elecciones de gobernador, llevadas a cabo en México, en los años 2010 y 2011. El artículo se puede consultar aquí. LZ hace un orden jerárquico de las casas encuestadoras, según la efectividad de éstas, atendiendo a tres criterios que luego comentaré.
Resultados oficiales de las elecciones a gobernador, según Leo Zuckermann.
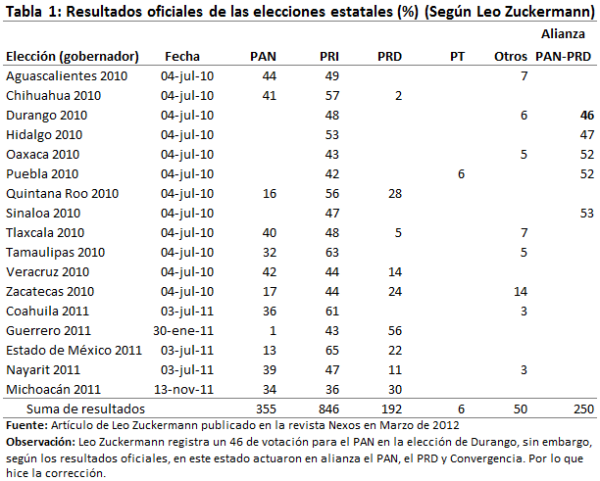
En la Tabla 1 aparecen los resultados oficiales, según LZ. Lo primero que se aprecia en esta tabla es que todos los valores son números enteros, lo cual es imposible de que ocurra, ya que estos valores son el resultado de un cociente donde el numerador y el denominador son del orden de cientos de miles o millones de votos.
Otra situación irregular es que, en 9 de las 17 las elecciones, el resultado para Otros Candidatos es cero. Esto no es posible de que ocurra, ya que Otros Candidatos es la suma de Votos Nulos y los correspondientes a Candidatos No Registrados, y a veces se le agrega la votación de algún partido pequeño, o algún partido grande en una elección donde tuvo una pobre votación. Lo anterior no es irrelevante puesto que casi la mitad de los puntos que le escamotea Zuckermann a Otros Candidatos, van a parar a los candidatos del PRI, y la otra mitad a los candidatos restantes, como se podrá ver en la siguiente sección y la Tabla 2. Esta conducta de LZ también la utilizan, por lo general, las casas encuestadoras: trasvasar puntos de Otros Candidatos, principalmente, a los candidatos del PRI, lo que se puede apreciar en artículos anteriores y más adelante en este artículo. A fin de cuentas ¿quién va a defender los votos de los candidatos no registrados y los votos nulos?
Resultados oficiales de las elecciones a gobernador.
Así las cosas, me di a la tarea de buscar los resultados oficiales en los sitios de internet de los institutos electorales estatales.
Los resultados, ahora si oficiales, se muestran en la Tabla 2. Se observa que, como la lógica indica, no hay un solo resultado electoral cuyo valor sea entero. También se tiene que, como se suponía, todos los resultados para Otros Candidatos son diferentes de cero, contrario a los resultados de LZ en la Tabla 1, para 9 de 17 elecciones.
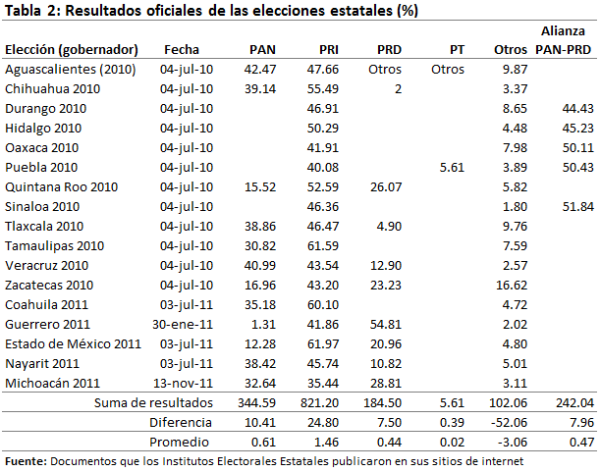
En la parte inferior de ambas tablas se tiene la suma de los resultados de las 17 elecciones estatales, para cada partido y cada alianza. En el caso de la Tabla 2 se presentan además el renglón Diferencia entre la Suma de resultados (según LZ) en la Tabla 1 menos la Suma de Resultados oficiales de la Tabla 2, así como el promedio de esas diferencias respecto al número de elecciones incluidas en el estudio (17). Lo que ahí se muestra es que todos los partidos y alianzas recibieron puntos de más (esto se puede verificar comparando los valores correspondientes en ambas tablas), a los únicos que se les quitaron puntos fue a Otros Candidatos. Al partido o alianza que más puntos le corresponden con los resultados “oficiales” de LZ es el PRI con 24.80 puntos, lo cual representa en promedio 1.46 puntos por cada elección estatal ¿les dice esto algo? Mientras a Otros Candidatos se le eliminaron 52.06 puntos porcentuales, el 51% de la votación total de Otros Candidatos en las 17 elecciones estatales. La pregunta es: ¿de dónde sacó LZ los resultados “oficiales” de la Tabla 1?
Leo Zuckermann cita en su artículo las dificultades que tuvo para recabar la información de las estimaciones de las casas encuestadoras. Y, en efecto, es difícil conseguir los reportes históricos de las encuestas electorales, sobre todo las estatales. Creo que la razón es que las casas encuestadoras tienen mucho que esconder, de otra forma, tendrían los reportes históricos de sus encuestas electorales disponibles en sus sitios de internet al alcance de cualquier ciudadano.
Debería existir una ley que obligara a los encuestadores a entregar sus reportes a los institutos electorales estatales, y que éstos los subieran a sus sitios de internet para quienes desearan consultarlos.
Propuestas de Leo Zuckermann para evaluar a las casas encuestadoras.
Transcribo las propuestas de Leo Zuckermann para evaluar a las casas encuestadoras, de su artículo aparecido en Nexos:
- En primerísimo lugar si aciertan al ganador. Ésta debe ser la variable central. Los electores queremos ver encuestas para tener esa información. Luego entonces, en la calificación que propongo habría que darle el peso mayor. En el ejercicio que presenta la tabla 10 le he dado un peso de 65% a esta variable.
- La segunda variable es cuántas últimas encuestas publicó el encuestador. Creo que hay que premiar a los que más publican por el riesgo que toman. De las 44 encuestas que analicé, 13 fueron de GCE (30%). A esta empresa, por tanto, le di la calificación mayor en esta variable que, en el ejercicio de la tabla 10, le asigné un 19% para el cálculo de la calificación final. GCE, luego entonces, recibió 1.9 para su calificación final. Las firmas que sólo publicaron una recibieron 0.146 puntos.
- La tercera variable tiene que ver con los errores en la diferencia entre el primero y el segundo lugares. Aquí le asigné un peso de 16% para la calificación final y, en aras de simplificar el cálculo, la encuestadora que tuvo el menor error (Síntesis) obtuvo la calificación mayor, es decir, 1.6 puntos para su calificación final, y así en orden descendente hasta llegar a la que presentó el mayor error (Indicadores) que se quedó con un cero.
Principios básicos que satisfacen las estimaciones de preferencia electoral.
En un anterior artículo (se puede consultar aquí), se establecía que las estimaciones de preferencia electoral en una encuesta tienen una distribución normal, por lo cual deben de satisfacer dos principios básicos:
- Los sesgos o desviaciones de las estimaciones tienen la misma probabilidad de ser positivos o negativos (propiedad de simetría)
- Es más probable observar sesgos pequeños que grandes.
Es decir, las desviaciones o sesgos de las estimaciones en relación a la preferencia electoral, tienen la misma probabilidad de ser positivas o negativas. Si se me permite la metáfora, podríamos decir que la distribución normal es democrática, no tiene preferencia por los sesgos positivos ni los negativos. La probabilidad de que se presenten es la misma. Y por otra parte, es más probable observar sesgos pequeños que sesgos grandes.
Postulado 1: Si se observa que los sesgos positivos tienen preferencia por un partido en particular, debemos estar ante la presunción de la manipulación de las estimaciones por parte de los encuestadores. Y más, si esta preferencia es sistemática, es decir, se repite con frecuencia la preferencia de los sesgos positivos hacia un partido en particular.
Validez de las estimaciones de las preferencias electorales.
Antes de tratar de evaluar el desempeño de las casas encuestadoras, y que sean merecedoras de una calificación, se tendría que averiguar si los datos son auténticos, es decir, si la variabilidad de las estimaciones o de los sesgos es producto del carácter aleatorio de los mismos (satisfacen los principios básicos I y II), o hay un componente importante que se puede explicar por la intervención humana para servir algún interés político.
Si los sesgos calculados de las estimaciones de las casas encuestadoras no satisfacen los dos principios antes comentados, estaríamos ante la sospecha, incluso certeza, dependiendo de la contundencia de las evidencias (probabilidad muy pequeña de que algún escenario se presente), de que los resultados son espurios (otra vez esa palabra) y, por tanto, se puede concluir que el sistema de medición de los encuestadores es incapaz e incluso, corrupto. Si este fuera el caso, no tendría sentido otorgarles una calificación.
Propuesta alternativa de evaluación de las encuestadoras.
Leo Zuckermann no toma en consideración la naturaleza estadística de los datos y el hecho de que las estimaciones de preferencia electoral tienen una distribución normal. Tampoco toma en cuenta la precisión con la cual dicen trabajar las casas encuestadoras, lo cual es fundamental para hacer una evaluación de su desempeño. Al parecer, en el punto (1), Zuckermann considera que un encuestador acierta al ganador, si su estimación para el candidato ganador es mayor que la del candidato que queda en segundo lugar, sin importar las magnitudes de las estimaciones y si están o no dentro de precisión.
Daré un ejemplo. En la elección a la gubernatura del estado de Hidalgo el resultado oficial para el candidato de la alianza PRI-PVE-PANAL fue de 50.29 puntos porcentuales, la estimación de GCE para esta alianza fue 63; por lo tanto, GCE tuvo un sesgo favorable a esta alianza de 12.71 puntos porcentuales. El resultado oficial para el candidato del PAN-PRD-CONV fue de 45.23, la estimación de GCE para esta alianza fue de 37 puntos porcentuales; por lo tanto, GCE tuvo un sesgo desfavorable a esta alianza de -8.23. Entonces, las dos estimaciones están fuera de precisión, y aun así Zuckermann le da un peso de 65% a GCE, porque, según él, acertó al ganador. En este caso, la diferencia oficial entre el primero y el segundo lugar es de 5.06, mientras que según GCE, esta diferencia sería de 26 puntos porcentuales. Evidentemente, este punto (1) de Zuckermann premia a la mayor parte –o a todos– los encuestadores de este grupo que beneficiaron sistemáticamente al PRI.
Desde mi punto de vista, si se trata de evaluar el desempeño de un grupo de encuestadores, el punto (2) que propone Zuckermann se puede sustituir por el siguiente:
(i) Que las casas encuestadoras entreguen su reporte de la encuesta al instituto electoral estatal o al IFE, según la elección sea estatal o federal. Que el correspondiente instituto electoral lo suba a su sitio de internet, con la mayor celeridad posible, para que se pueda consultar por cualquier ciudadano o investigador.
Los puntos (1) y (3) de Zuckermann, se pueden sustituir por el siguiente punto que propongo.
(ii) Que se vayan acumulando, elección tras elección, el número de estimaciones de las casas encuestadoras con sus correspondientes precisiones para que, de esta manera, se calcule el porcentaje histórico de las estimaciones para los diferentes candidatos las cuales se encuentran dentro de precisión (este sería el porcentaje de candidatos a los cuales han acertado su resultado). A medida que transcurran las elecciones, si los encuestadores son honestos y profesionales, este porcentaje debe oscilar alrededor del 95%, que es el nivel de confianza[1] con el cual trabajan los encuestadores usualmente.
(iii) Que se acumulen, elección tras elección, el porcentaje de sesgos positivos de un encuestador para un partido o alianza en particular. Al ir aumentando el número de elecciones el porcentaje de sesgos positivos de un encuestador por un partido en particular, debe acercarse a el 50 por ciento (en virtud de que la probabilidad de observarse un sesgo positivo o negativo es la misma, es decir, 0.5, en virtud de que las estimaciones de preferencia electoral tienen una distribución normal).
Algunos gráficos para analizar la validez y confiabilidad de las estimaciones de las casas encuestadoras.
Me di a la tarea de recabar la información de los resultados oficiales de las 17 elecciones estatales en sus respectivos institutos electorales, los cuales se muestran en la Tabla 2. Las estimaciones de las casas encuestadoras las tomé de las recopiladas por Zuckermann en su artículo, y aunque éste las presenta a todas como cifras enteras, creo que buscar las cifras precisas sería bastante tardado y, finalmente, no cambiarían en forma importante los escenarios que se presentan a continuación.
Con base a los resultados oficiales que se presentan en la Tabla 2, y las estimaciones de las casas encuestadoras que presenta en su artículo Leo Zuckermann, realicé una serie de gráficos para analizar el desempeño de las casas encuestadoras en las 17 elecciones estatales mencionadas.
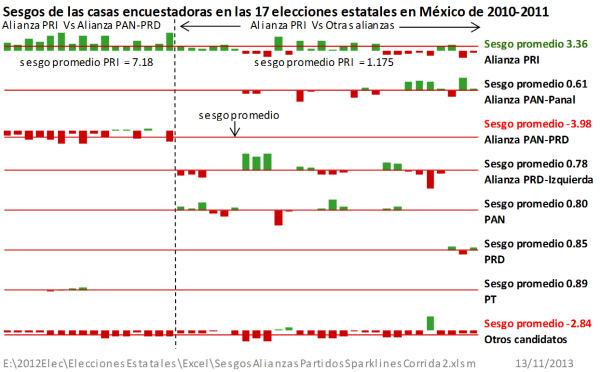
Figura 1
En la Figura 1, se tienen los sesgos de las casas encuestadoras para los diferentes partidos y alianzas en 17 elecciones a gobernador, realizadas en los años de 2010 y 2011. Se tienen 44 sesgos, producto de 44 estimaciones. Solamente la Alianza PRI y Otros Candidatos tienen las 44 mediciones de sesgo. El PAN, por ejemplo, aparece en alianza, en unas ocasiones con el PANAL, en otras con el PRD y otros partidos de izquierda, y en otras elecciones aparece solo, por eso los 44 sesgos aparecen distribuidos en las diferentes alianzas y en las que actuó solo. Lo mismo ocurre con los otros partidos.
Los sesgos son significativamente desfavorables hacia Otros Candidatos y la alianza PAN-PRD. Resulta que, de 44 sesgos, 32 son positivos y, por tanto, favorables al PRI (72.7% de sesgos positivos). En tanto que de 16 sesgos, solamente 3 son positivos para la alianza PAN-PRD (18.7% de sesgos positivos). Para Otros Candidatos, de 44 sesgos, sólo 4 son positivos (9.09% de sesgos positivos). Lo que se observa es que los encuestadores beneficiaron a la alianza del PRI en detrimento de Otros Candidatos, en primer lugar, y de la alianza PAN-PRD, en segundo lugar. En cada estimación de las casas encuestadoras, en las 17 elecciones estatales, el PRI recibió un sesgo favorable promedio de 3.36. En tanto que Otros Candidatos en cada estimación recibieron en promedio un sesgo desfavorable de -2.84 puntos porcentuales. La alianza PAN-PRD tuvo un sesgo promedio desfavorable de -3.98.
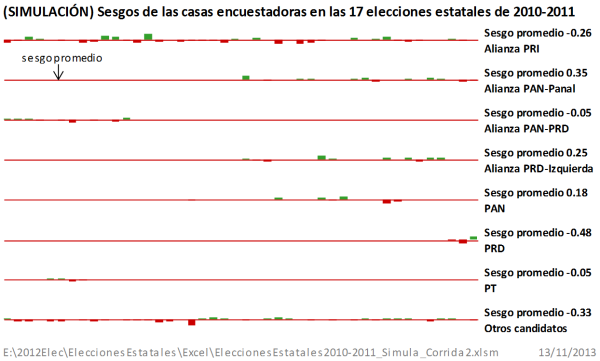
Figura 2
Aunque desconozco la precisión con la que trabajaron las casas encuestadoras en sus encuestas en las 17 elecciones, hice un ejercicio suponiendo que todos trabajaron con una precisión de 2.5 por ciento, la cual es una precisión muy cercana a la precisión con la cual trabajan los encuestadores, que es generalmente entre 2 y 3 por ciento. El resultado de esta simulación se muestra en la Figura 2.
En la Figura 1 se puede observar que, en esas 17 elecciones, los sesgos son favorables a la alianza del PRI en forma significativa. No solamente en el número de sesgos favorables, sino en la magnitud de éstos. Una comparación visual de las Figuras 1 y 2, nos da una idea del nivel de manipulación a las que sometieron las casas encuestadoras a sus estimaciones.
En la Tabla 3 se tiene un resumen numérico donde se calcula la probabilidad de cada escenario observado para las diferentes alianzas y partidos. Se puede observar como el escenario donde resultan muy perjudicados Otros Candidatos, es prácticamente imposible de ocurrir en un sistema de medición honesto. Mientras que los escenarios donde sale beneficiada la Alianza del PRI y perjudicada la alianza PAN-PRD, son muy poco probables de ocurrir.
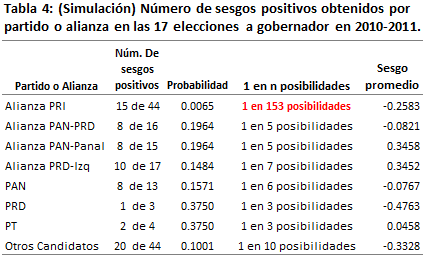
En la Tabla 4 se muestra el resumen del número de sesgos positivos obtenidos mediante simulación, los cuales se exhiben gráficamente en la Figura 2. Se puede apreciar como los diferentes escenarios tienen una probabilidad razonable de ocurrir. También se tiene que el sesgo promedio por alianza o partido tiene una variabilidad menor que las obtenidas por las casas encuestadoras mostradas en la Tabla 3. Los sesgos promedio están contenidos en el intervalo que va de -0.5 a 0.5. No se observa una intencionalidad de beneficiar a algún candidato en particular, como se observa en los sesgos reales obtenidas por las casas encuestadoras y mostrados en la Figura 1 y la Tabla 3. El único escenario con poca probabilidad de ocurrir en la Tabla 4, es el de la Alianza PRI, que es 1 posibilidad en 153, sin embargo, el sesgo promedio es de sólo -0.2583; a diferencia de los sesgos obtenidos por las casas encuestadoras, los cuales se muestran en la Figura 1 y la Tabla 3 (El escenario mostrado en la Figura 2 y resumido en la Tabla 4, fue producto de una simulación. Si se realizara otra simulación los resultados serían diferentes, pero en general, se repetirían los principios (I) y (II) enunciados anteriormente).
Situación similar en la intencionalidad de los sesgos en las 17 elecciones a la gubernatura en 2010-2011 y las elecciones presidenciales de 2012.
En las siguientes tres figuras se puede apreciar un comportamiento muy similar de los sesgos de las diferentes alianzas y partidos, en las 17 elecciones a la gubernatura, en los años de 2010-2011, y en la elección a la presidencia de la república en el año de 2012. Esto hace pensar en una acción concertada de las casas encuestadoras y sus patrocinadores, para beneficiar a los candidatos del PRI, solos o en alianza, y perjudicar, principalmente, y de manera sistemática, a Otros Candidatos. En la elección presidencial de 2012 también se benefició sistemáticamente a Gabriel Quadri y se perjudicó de la misma manera a Josefina Vázquez Mota. He mostrado en artículos anteriores que, a través de la campaña electoral presidencial de 2012, las estimaciones de la mayor parte de los encuestadores estuvieron beneficiando exageradamente a Enrique Peña Nieto y perjudicando también en el mismo grado a López Obrador.
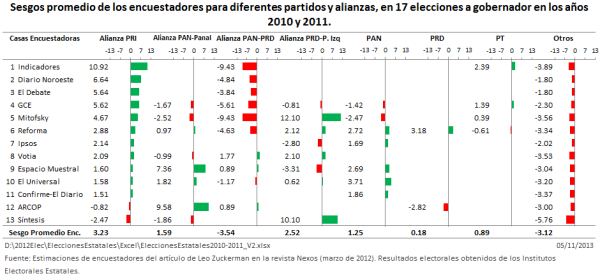
Figura 3
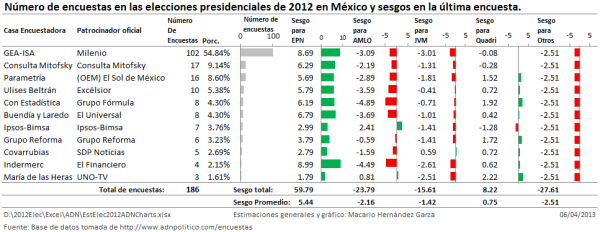
Figura 4
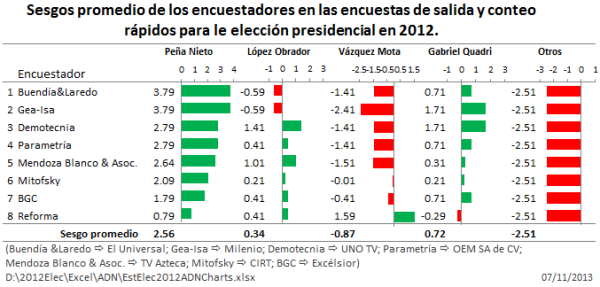
Figura 5
Desconozco las precisiones con las que trabajaron o dijeron trabajar las casas encuestadoras en las 17 elecciones a gobernador en los años 2010 y 2011. Pero haciendo un ejercicio elemental, se tiene que, el 61.36% de las estimaciones que se tomaron en las 17 elecciones a la gubernatura para la alianza PRI, tienen un sesgo favorable a esa alianza mayor o igual al 2.5% y, puesto que los encuestadores trabajan típicamente con una precisión de entre 2% y 3%) podemos asumir que, aproximadamente el 61.36% de las estimaciones estuvieron fuera de precisión para la Alianza PRI en las elecciones a gobernador antes citadas. Hipotéticamente, el 61.36% de las estimaciones de preferencia electoral estuvieron fuera de precisión para los candidatos de la Alianza PRI, el cual no solamente es un escenario prácticamente imposible de ocurrir de manera honesta, sino que además estuvieron fuera de precisión favoreciendo a la Alianza PRI. Se esperaría que sólo el 2.5% de los sesgos estuviera fuera de precisión beneficiando a un candidato dado, cuando se trabaja a un nivel del 95% de confianza. La probabilidad de que se presente este escenario para los candidatos de la Alianza del PRI es: 2.47746X10-32, algo prácticamente imposible de ocurrir.
En el caso de la última encuesta de la elección presidencial, cuyos sesgos se muestran en la Figura 4, se tiene que el 72.72% (8 de 11) de las estimaciones para Peña Nieto estuvieron fuera de precisión y favoreciéndolo. Mientras que en las encuestas de salida y conteos rápidos (Figura 5) el 87.5% (7 de 8) de las estimaciones para Peña Nieto también estuvieron fuera de precisión y favoreciéndolo. Cuando digo que una estimación está fuera de precisión y favoreciendo a un candidato, significa que la estimación es mayor al resultado oficial del candidato y la diferencia entre la estimación y el resultado oficial es mayor que la precisión con la cual el encuestador dijo trabajar.
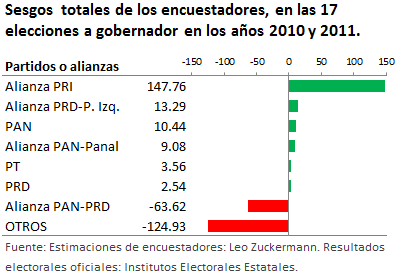
Figura 6
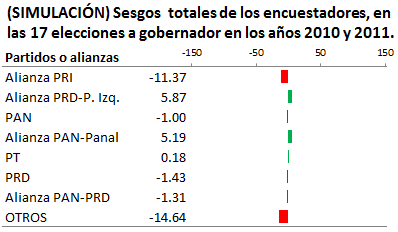
Figura 7
En la Figura 6 se muestran los sesgos totales obtenidos por las casas encuestadoras para las diferentes alianzas y partidos, en las 17 elecciones a gobernador en los años 2010 y 2011. Se puede observar que el principal beneficiado, y con mucho, fue la Alianza PRI. Los principales afectados: Otros Candidatos y Alianza PAN-PRD.
En la Figura 7 se muestran los sesgos totales obtenidos mediante simulación por las casas encuestadoras. Si comparamos las Figura 6 y 7, podemos dilucidar fácilmente cual es el escenario manipulado.
Los sesgos favorables a la Alianza PRI fueron significativamente mayores cuando contendió contra la alianza PAN-PRD.
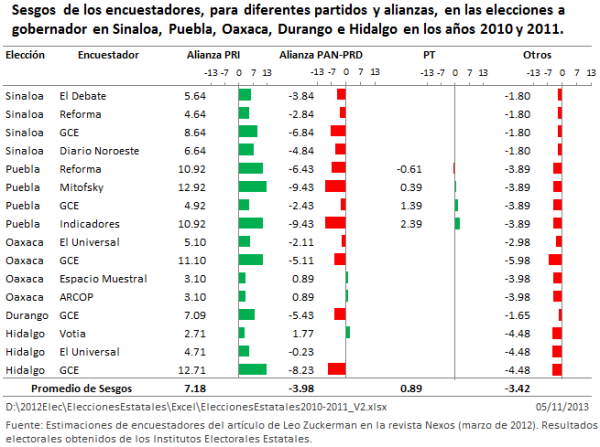
Figura 8
Otro elemento importante a considerar es que el sesgo promedio de la alianza del PRI fue 7.18 en las elecciones donde contendió contra la alianza del PAN-PRD, mientras que el promedio de la alianza del PRI en las elecciones restantes fue de 1.175. Y el promedio del sesgo global de la alianza del PRI fue de 3.36. Es decir, el sesgo promedio, favorable al PRI, fue 6.11 veces más grande cuando contendió contra la alianza PAN-PRD que en las elecciones restantes a la gubernatura. Lo que indica que en las elecciones donde la alianza del PRI contendió contra una alianza fuerte, los encuestadores le dieron sesgos favorables significativamente mayores a la alianza PRI. Esto confirma que la magnitud y el signo de los sesgos producidos por las casas encuestadoras obedece a una intencionalidad (típico de un sistema de encuestadores amafiado), y no a la aleatoriedad y a la distribución normal de los mismos, como debería de ser en un sistema honesto de medición.
El caso extremo es la elección de Puebla a la gubernatura, donde 3 de 4 estimaciones tuvieron un sesgo favorable al PRI mayor de 10 puntos porcentuales, como se puede ver en la Figura 8.
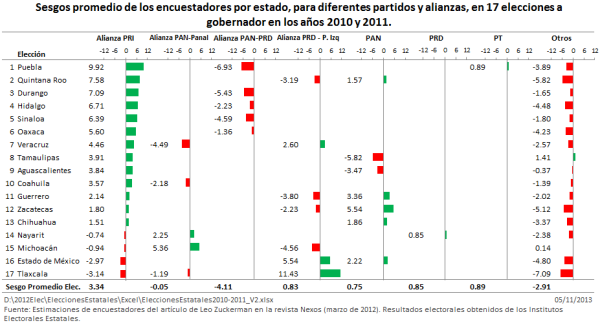
Figura 9
A manera de conclusión.
En su artículo publicado en Nexos, Leo Zuckermann afirma: “En México tenemos una industria de las encuestas de clase mundial. Lo que nos falta es la evaluación de los distintos encuestadores por parte de la sociedad”. Si entendemos a una empresa de clase mundial como una empresa que puede competir en eficiencia y calidad con cualquiera otra en el mundo, estoy en desacuerdo con la aseveración de Zuckermann. En éste y en anteriores artículos se ha mostrado la falta de aleatoriedad de las estimaciones de las casas encuestadoras, y la intencionalidad en las estimaciones para beneficiar en forma abrumadora al PRI o a las alianzas en que ha participado.
Con lo que hemos visto hasta aquí, no hay necesidad de calificar las estimaciones de las casas encuestadoras: las estimaciones de éstas se descalifican a sí mismas y a los encuestadores que las producen. A mi parecer las estimaciones de las casas encuestadoras no son auténticos, por la improbabilidad de los escenarios producidos por sus sesgos, así como por la intencionalidad que en ellos se percibe. El conjunto de casas encuestadoras, es un sistema de medición el cual, globalmente, estuvo confabulado para beneficiar a los candidatos del PRI, solos o en sus alianzas, por lo menos en las elecciones estatales de 2010 y 2011, y en la elección presidencial de 2012.
No es que la mayoría de los políticos sean extremadamente incompetentes, es que gobiernan para beneficiar a los banqueros y las grandes empresas, que al final, forman parte del gobierno o de un metagobierno, o como está de moda decir, de los poderes fácticos, porque, finalmente, son los que mandan. De la misma forma ocurre con las casas encuestadoras, no es que sean incompetentes, estas hacen su “trabajo” para beneficiar a los candidatos de ese metagobierno.
Ahora bien, si Leo Zuckermann entiende a “una industria de las encuestas de clase mundial” como aquella que es capaz de publicar resultados que obedezcan a los deseos de sus clientes, pues no me queda más remedio que darle la razón. Los perritos dan obedientemente la patita ante la orden de su amo.
De nuevo, un especial agradecimiento a Daniel González Sepúlveda, por la revisión y corrección de este escrito, así como por sus aportaciones al mismo.
[1]Nivel de Confianza: Si un encuestador está trabajando con un nivel de confianza del 95% y una precisión del 2%. Esto significa que, si se repitiera el muestreo un número grande de veces, se espera que, aproximadamente, en un 95% de ocasiones, la preferencia electoral estimada estuviera a una distancia de 2 puntos porcentuales o menos de la preferencia electoral real. Es decir, en un 95% de las ocasiones, sus estimaciones estarían dentro de precisión.
Por Macario Hernández Garza.
Continuamos con la sexta parte del análisis de las estimaciones de las casas encuestadoras en las elecciones del 2012 en México. Ahora con el análisis de las estimaciones para Josefina Vázquez Mota, con base a los resultados recopilados por ADNPolítico y publicados en su sitio de internet, en la liga: www.adnpolitico.com/encuestas. Como se ha comentado, a estas estimaciones se le añadieron las de Indermerc-Harris, las cuales se tomaron de los reportes entregados por esta encuestadora al IFE.
Análisis de las estimaciones para Josefina Vázquez Mota.
Curva de estimaciones de todas las casas encuestadoras (estimaciones juntas o agregadas).
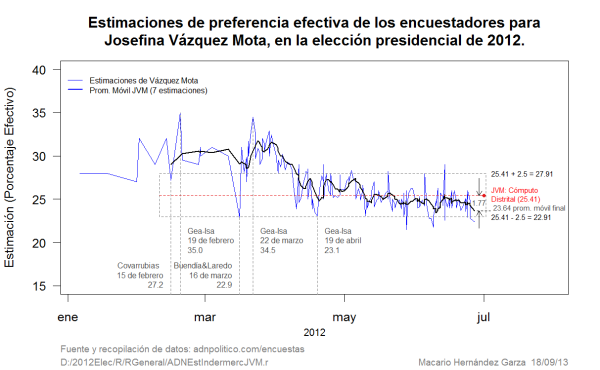
Figura 1
En la Figura 1 se tienen las estimaciones de las diferentes casas encuestadoras para Josefina Vázquez Mota. Como ocurrió con las estimaciones de Peña Nieto y López Obrador, hay picos en algunas estimaciones con diferencias cercanas a los 10 puntos porcentuales con respecto a los otros encuestadores. Buendía y Laredo tenía para Vázquez Mota 22.9 puntos porcentuales el 16 de marzo, mientras que Gea-Isa reportaba 34.5 para esta misma candidata el 22 de marzo; una diferencia de 11.6 puntos porcentuales en seis días.
Las curvas de estimaciones por casa encuestadora (estimaciones por separado o desagregadas).
En la Figura 2, se tienen las estimaciones de las casas encuestadoras en forma separadas o desagregadas, es decir, se grafican las estimaciones de cada encuestador en una curva individual. Con ello se consigue exhibir la conducta de cada encuestadora.
Se puede ver en la Figura 2 como hay una táctica de la mayor parte de las casas encuestadoras de tener, al inicio de la contienda, sobrevaluada en sus estimaciones a Josefina Vázquez Mota. Esta táctica se aprecia, principalmente, en nuestra vieja conocida Gea-Isa.
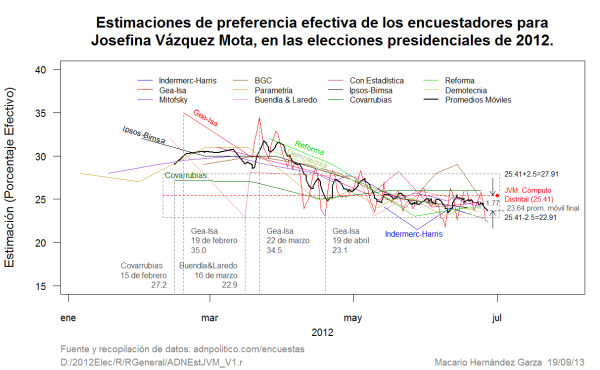
Figura 2
Se observa en la Figura 2, cómo inicia Gea-Isa con las estimaciones más altas para Vázquez Mota, igual que lo hizo con Enrique Peña Nieto, sólo que para este candidato mantuvo los sesgos favorables hasta el final. En la misma Figura 2 se aprecia que la mayor parte de las casas encuestadoras jugaron la estrategia de traer inicialmente a Vázquez Mota con estimaciones sobrevaluadas, para luego llevarla a su nivel real y, posteriormente, terminar castigándola con estimaciones con sesgos negativos; pero los puntos que le otorgaron en exceso a Peña Nieto, de algún candidato los tenían que sacar, y los sacaron, por orden de magnitud de: Otros Candidatos, López Obrador y Josefina Vázquez Mota.
La mayor parte de las casas encuestadoras, de enero a abril de 2012, aproximadamente, trataron de sembrar la idea de que la disputa por la presidencia estaba entre Enrique Peña Nieto y Josefina Vázquez Mota. Con ello, trataban de hacer que el efecto de arrastre o Bandwagon beneficiara a estos dos candidatos.
Nuevamente, para desgracia de la mayoría de las casas encuestadoras, Covarrubias pone en serios predicamentos, con sólo 5 estimaciones, la historia de las demás casas encuestadoras de que Vázquez Mota traía estimaciones de entre 30 y 35 puntos porcentuales hasta el mes de abril de 2012. La estimación final de Covarrubias fue la segunda mejor estimación para Vázquez Mota. El rango de variabilidad de las estimaciones de Covarrubias fue de sólo 2.2 puntos porcentuales (con sólo cinco estimaciones), contra un rango de variabilidad correspondiente de Gea-Isa de 13.2 puntos porcentuales (6 veces más grande que el de Covarrubias y con 103 estimaciones).
Resulta también contradictorio que Covarrubias con un tamaño de muestra de 1500, su estimación final para Vázquez Mota estuvo a una distancia de 0.59 puntos porcentuales del resultado final, mientras que el promedio móvil final, basado en las últimas 7 estimaciones y en un tamaño de muestra de 7950, esté a una distancia de 1.77 puntos porcentuales. Llama también la atención que, Covarrubias, con sólo 5 encuestas, tenga un mejor desempeño que Gea-Isa, la cual realizó 103 encuestas.
Otro punto a considerar es que, de todas las estimaciones de Covarrubias para Vázquez Mota, la más alejada estuvo a 1.79 puntos porcentuales y corresponde al 15 de febrero de 2012. Lo anterior hace pensar que las preferencias electorales para Vázquez Mota fueron bastante estables y que la historia contada por la mayoría de las casas encuestadoras no es verídica.
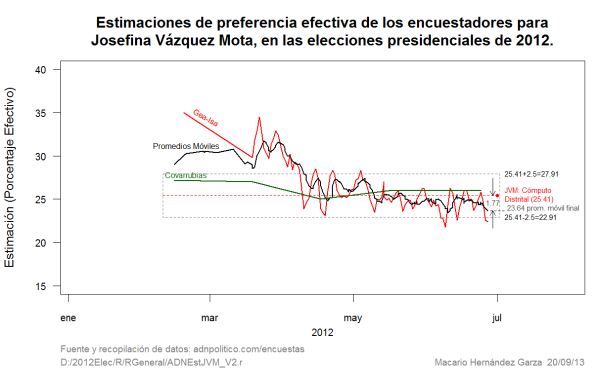
Figura 3
En la Figura 3 se muestran las curvas de las estimaciones de Gea-Isa, Covarrubias y los Promedios Móviles basados en las últimas siete estimaciones a la fecha dada. En la figura mencionada se contrastan las estimaciones de las encuestadoras que tuvieron el peor y el mejor desempeño en las estimaciones de Vázquez Mota.
Asimismo, en esta figura se puede apreciar como las curvas de Gea-Isa y Covarrubias son muy diferentes. Por una parte se observa la estabilidad de las estimaciones de Covarrubias contra la enorme variabilidad de las de Gea-Isa. La curva de Gea-Isa parece una sierra dentada, una curva muy nerviosa, donde en menos de una semana sube 5 puntos, y en esa misma semana los vuelve a bajar.
La última estimación de Covarrubias tuvo un error o sesgo en su última estimación de sólo 0.59 puntos porcentuales contrastando con el error de -3.01 de Gea-Isa.
La Figura 4 muestra la conducta de las estimaciones de las casas encuestadoras en las estimaciones para Vázquez Mota. Las líneas horizontales representan el rango de variabilidad de las estimaciones de las distintas casas encuestadoras. Los puntos rojos representan la última estimación reportada, mientras que la línea vertical punteada representa el resultado del cómputo distrital para Vázquez Mota. A la izquierda de cada línea horizontal, aparecen dos valores numéricos: el primero representa el rango de variabilidad de las estimaciones durante la campaña electoral y, el segundo, el sesgo final, la diferencia entre la última estimación y el resultado del cómputo distrital para Vázquez Mota.
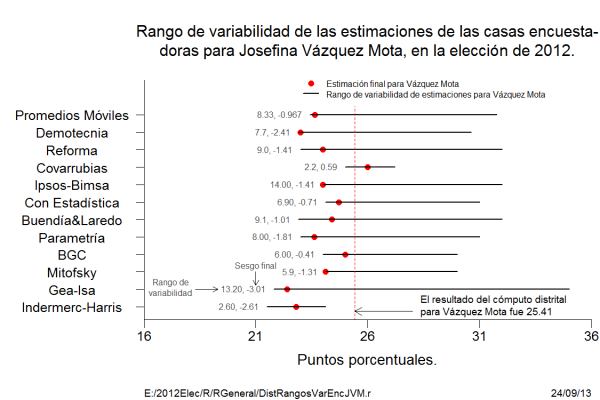
Figura 4
Usando la metáfora de que el grupo de estimaciones de un encuestador para un candidato dado es la película de cómo se movieron las preferencias electorales durante la campaña electoral, se puede observar que la película contada por Covarrubias es muy diferente de las películas contadas por las otras casas encuestadoras. Como se puede ver en la Figura 4, el rango de variabilidad de las estimaciones de Covarrubias es de 2.20 puntos porcentuales, y además, tiene un sesgo o error de sólo 0.59 puntos porcentuales para Vázquez Mota. El rango de variabilidad de las estimaciones de Gea-Isa fue de 13.20, 5 veces más grande que el valor correspondiente de Covarrubias.
En un anterior artículo (se puede consultar aquí), se establecía que las estimaciones de una encuesta electoral deben de satisfacer dos principios básicos: (I) Los sesgos o desviaciones de las estimaciones tienen la misma probabilidad de ser positivos o negativos (propiedad de simetría) y, (II) Es más probable observar sesgos pequeños que grandes. Si se observa la Figura 4, se tiene que las estimaciones finales (puntos rojos), violan estos dos principios.
Como dato adicional se tiene que, de las once casas encuestadoras, dos de las estimaciones estuvieron fuera de precisión y con sesgo negativo. La probabilidad que de 11 estimaciones, 2 estén fuera de precisión (Gea-Isa e Indermerc-Harris), es de una posibilidad en 12, de manera conservadora; de manera estricta sería 0.0273, una posibilidad en 36.
Si observamos la Figura 4, 10 de las 11 estimaciones de las casas encuestadoras para Vázquez Mota son menores que el resultado final del Cómputo Distrital (la probabilidad de que esto ocurra es 0.00537 una posibilidad en 186), lo que contradice el principio (I), establecido en el párrafo anterior. Además, hay más estimaciones alejadas del resultado del Cómputo Distrital para Vázquez Mota, que valores cercanos, lo que contradice el principio (II), antes establecido.
¿Pertenece México a una región bizarra o anómala del Universo?
Hemos visto en este artículo y los anteriores, que pareciera que México perteneciera a una región anómala o bizarra del universo, una región donde la estadística no se cumple: los escenarios más improbables son los más frecuentes de ocurrir, y por tanto, los escenarios más probables no ocurren. Ni Juan Orol hubiese podido crear un argumento más absurdo. Pero como escribiera Víctor Romero Rochín, en uno de sus estudios sobre anomalías electorales en las elecciones de 2006: cuando se interfiere con el azar, se nota.
Como se ha visto en esta serie de artículos, las casas encuestadoras, más que medir el pulso de la opinión pública, lo van moldeando, junto con los medios de comunicación, de acuerdo a los intereses de la agenda de los poderes fácticos nacionales e internacionales.
¿Qué sigue?
Creo estar cerca del final de esta serie de artículos, sobre el análisis de las estimaciones de las casas encuestadoras, para los candidatos en las elecciones presidenciales de 2012. Pienso escribir alrededor de tres artículos más. En estos artículos haré un resumen de las estimaciones para los distintos candidatos y lo relacionaré con algunas elecciones de 2010, para ver las conductas de las casas encuestadoras en esas elecciones. Analizaré la propuesta que Leo Zuckermann hace en la revista Nexos, para evaluar la actuación de las casas encuestadoras. Y haré un análisis sobre un artículo, que escribió Ulises Beltrán hace cerca de 20 años en la revista Nexos, para tratar de mostrar que la manipulación de los encuestadores políticos, nació con la aparición de estos en el escenario político.
Mientras tanto, agradezco su atención y paciencia.
Nuevamente, un especial agradecimiento a Daniel González Sepúlveda, por la revisión de este escrito, así como por sus correcciones y aportaciones al mismo.
Estar gobernados por el dinero organizado es tan peligroso como estarlo por el crimen organizado.
Franklin D. Roosevelt.
Por Macario Hernández Garza.
Continuamos con la quinta parte del análisis de las estimaciones de las casas encuestadoras en las elecciones del 2012 en México. Ahora con el análisis de las estimaciones para Andrés Manuel López Obrador. Con base a los resultados recopilados por ADNPolítico y publicados en su sitio de internet, en la liga: www.adnpolitico.com/encuestas. Como se ha comentado, a estas estimaciones se le añadieron las de Indermerc-Harris, las cuales se tomaron de los reportes entregados por esta encuestadora al IFE.
Análisis de las estimaciones de Andrés Manuel López Obrador.
Curva de estimaciones de todas las casas encuestadoras (estimaciones juntas o agregadas).

Figura 1
En la Figura 1 se tienen las estimaciones de las diferentes casas encuestadoras para López Obrador. Se puede observar que hay picos en algunas estimaciones con diferencias de alrededor de 10 puntos porcentuales con respecto a los otros encuestadores. Estos picos corresponden, generalmente, a Demotecnia, Covarrubias y Reforma. Estas tres casas encuestadoras fueron cuestionadas severamente por los otros encuestadores, en el sentido que sus estimaciones discrepaban con la mayor parte de las casas encuestadoras, por lo que se argumentaba que estos encuestadores debían explicar tales diferencias. Cuando resultó que la mayor parte de estos encuestadores vociferantes quedaron muy lejos del resultado oficial, curiosamente, no explicaron sus diferencias, como antes se lo habían exigido, sólo dieron excusas inverosímiles.
Los que se observa de la Figura 1, es que la mayor parte de las casas encuestadoras tuvieron para López Obrador la conducta contraria que tuvieron para Peña Nieto. Este grupo mayoritario de casas encuestadoras siempre estuvieron favoreciendo a Peña Nieto con estimaciones con sesgos positivos, mientras que con López Obrador, lo estuvieron perjudicando con estimaciones con sesgos negativos.
Las curvas de estimaciones por casa encuestadora (estimaciones por separado o desagregadas).

Figura 2
En la Figura 2, se muestran las estimaciones de las casas encuestadoras en forma separadas o desagregadas, es decir, se grafica las estimaciones de cada encuestador en una curva individual. Con lo anterior se consigue exhibir la conducta individual de cada casa.
Se puede ver en las Figuras 1 y 2 como, a partir del mes de mayo, la curva de promedios móviles de las estimaciones para López Obrador empieza a tener una tendencia creciente, pero seguramente, no porque haya ocurrido algo que hizo que Obrador estuviera incrementando su preferencia electoral, sino que lo tenían tan subvaluado, que no tuvieron más remedio que empezar a aumentar sus estimaciones para no quedar tan rezagados respecto al resultado final.
La táctica fue favorecer con sus estimaciones a Peña Nieto y perjudicar a López Obrador, para desalentar a los votantes de López Obrador e influir en parte de los votantes independientes a inclinarse por Peña Nieto. Y con ello, producir el efecto Bandwagon, es decir, impulsar a que votaran por Peña Nieto los ciudadanos que, tradicionalmente, se suben al carro del candidato del que se dice en los medios, será ganador. El efecto Bandwagon también incide en los grandes contribuyentes a las campañas electorales, quienes le inyectan cuantiosos recursos económicos al candidato que señalan las encuestas como puntero.
El siguiente extracto, tomado de Wikipedia (http://es.wikipedia.org/wiki/Efecto_arrastre), nos habla acerca del efecto Bandwagon o “efecto arrastre” y su manifestación en la política:
Origen de la frase
El término bandwagon es un anglicisismo que significa un carro que lleva una banda en un desfile, circo u otro espectáculo. La frase «Salta en el bandwagon» fue usada por primera vez en la política estadounidense allá en 1848 por causa de Dan Rice, bufón personal de Abraham Lincoln. Dan Rice, un payaso profesional de circo, usó su bandwagon para las apariciones de la campaña de Zachary Taylor para ganar atención al usar música. Conforme la campaña de Taylor se hizo más exitosa, más políticos se esforzaron por conseguir un asiento en el bandwagon, en espera de asociarse con el éxito. Más tarde, en 1900, durante la época de la campaña presidencial de William Jennings Bryan, los bandwagons se habían convertido en el estándar en las campañas, y ‘subirse al carro’ fue usado como un término desviado que implicaba que la gente se asociaba a sí misma con el éxito sin considerar lo que asociaban a sí mismos con él.
Uso en Política
El efecto bandwagon ocurre durante la votación: algunas personas votan por aquellos candidatos o partidos que es probable que resulten ganadores (o que son proclamados como tales por los medios de comunicación), esperando estar en el ‘lado ganador’ al final. El efecto bandwagon ha sido aplicado a situaciones que involucran a la opinión de la mayoría, como es el caso de los resultados políticos, donde la gente modifica sus opiniones de acuerdo al punto de vista de la mayoría (McAllister and Studlar 721). Un cambio tal de opinión puede ocurrir debido a que los individuos trazan inferencias de las decisiones de los otros, como en una cascada de información.
Varios estudios han puesto a prueba esta teoría del efecto bandwagon en la toma de decisiones políticas. En el estudio de 1994 de Robert K. Goidel y Todd G. Shields en The Journal of Politics, 180 estudiantes de la Universidad de Kentucky fueron asignados al azar a nueve grupos y les consultaron cuestiones sobre el mismo conjunto de escenarios de elección. Alrededor de 70% de los sujetos recibieron información sobre el ganador esperado (Goidel and Shields 807). Los independientes, que fueron aquellos que no votaron basados en el respaldo de ningún partido y son, en última instancia, neutrales, son influenciados fuertemente en favor de la persona que se espera ganará (Goidel and Shields 807-808). Las expectativas desempeñan un rol significativo en todo el estudio. Se encontró que es dos veces más probable que los independientes voten por el candidato republicano cuando se espera que los republicanos ganen. A partir de los resultados, también se encontró que cuando se espera que ganen los demócratas, era más probable que los republicanos independientes y los republicanos débiles votaran por el candidato demócrata (Goidel and Shields 808).
Como podemos ver, el efecto bandwagon y su manifestación en la política, particularmente en las elecciones, es un fenómeno estudiado y verificado, de tal suerte que el hecho de que la mayor parte de las encuestadoras trajeran durante toda la campaña a Enrique Peña Nieto con estimaciones con exagerado sesgo positivo, seguramente fue para aprovechar el efecto bandwagon producido sobre los electores y los grandes donantes a la campaña electoral (los poderes fácticos o la delincuencia organizada, aunque cada vez es más difícil diferenciar a unos de otros), y con ello beneficiar a Peña Nieto.
Se puede observar en la Figura 2 que, como pasó en el caso de Peña, también para el caso de López Obrador, Demotecnia desnuda la actuación del resto de las casas encuestadoras.
Las estimaciones de Demotecnia tuvieron un rango de variabilidad de sólo 3.20 puntos porcentuales, a diferencia de la batería mayoritaria de encuestadores. A juzgar por las primeras estimaciones de Covarrubias, 30.2 puntos porcentuales para López Obrador el 15 de febrero, y Demotecnia, 29.2 el 27 de marzo, se puede advertir que, entre enero y abril, la mayor parte de encuestadores traían a López Obrador casi 10 puntos porcentuales por debajo de estas casas encuestadoras y, probablemente, del valor de estimación cercano al que realmente tenía López Obrador. Demotecnia, al final, fue la casa encuestadora con la segunda estimación más cercana al resultado oficial para López Obrador, estuvo a 0.81 puntos porcentuales del resultado oficial que fue de 31.59.
Más aún, Demotecnia tuvo uno de los mejores desempeños, con sólo 3 encuestas realizadas, contrastando con las 102 de Gea-Isa con pésimos desempeño estadístico pero, seguramente, con gran éxito financiero. Gea-Isa jugó el papel que se le asignó en el reparto, junto con las otras casas encuestadoras.
Se puede ver, también en la Figura 2, como tanto Covarrubias como Reforma, tuvieron una estimación donde “coquetearon” con las estimaciones de la mayoría de las casas encuestadoras. Se pueden observar también, los apuros de Ipsos-Bimsa por desmarcarse de la mayor parte de las casas encuestadoras.
La última estimación de promedio móvil producida por las últimas 7 estimaciones de las casas encuestadoras en junio de 2012, está basada en un tamaño de muestra de 7,950 (la suma del tamaño de muestra de las últimas 7 encuestas). Una estimación basada en una muestra de este tamaño debería tener un error máximo muy cercano al 1.0%. La última estimación de promedio móvil para López Obrador fue de 29.14, lo cual da un error de -2.45 que resulta de la diferencia entre 31.59 y 29.14, que es casi 2.5 veces el error máximo de 1.0%, como se puede apreciar en la Figura 2. Y este error negativo resulta de las estimaciones con sesgos negativos de la mayor parte de las casas encuestadoras para López Obrador. Resulta contradictorio que Demotecnia con un tamaño de muestra de 1,500, tenga un error 0.81 y que el error del último promedio móvil con un tamaño de muestra total de 7,950 resulte en un error de -2.45. Como antes se comentó para el caso de Peña Nieto: ¿El mundo al revés? No, simple manipulación de las estimaciones.
Gráfico de rangos de variabilidad y estimación final por casa encuestadora.

Figura 3
La Figura 3 exhibe, desde otra perspectiva, la conducta de las estimaciones de las casas encuestadoras en las estimaciones para López Obrador. Las líneas horizontales representan el rango de variabilidad de las estimaciones. Los puntos rojos representan la última estimación reportada, mientras que la línea vertical punteada representa el resultado del cómputo distrital para López Obrador. A la izquierda de cada línea horizontal, aparecen dos valores numéricos: el primero representa el rango de variabilidad de las estimaciones durante la campaña electoral y, el segundo, el sesgo final, la diferencia entre la última estimación y el resultado del cómputo distrital para López Obrador.
Usando la metáfora de que el grupo de estimaciones de un encuestador para un candidato dado es la película de cómo se movieron las preferencias electorales durante la campaña electoral, se puede observar que la película contada por Demotecnia es muy diferente de las películas contadas por las otras casas encuestadoras. Como se puede ver en la Figura 3, el rango de variabilidad de las estimaciones de Demotecnia es de 3.20 puntos porcentuales, y además, tiene un sesgo o error de sólo 0.81 puntos porcentuales para López Obrador.
Para desgracia de las otras casas encuestadoras, la actuación de Demotecnia, en el caso de López Obrador y Peña Nieto, pone en evidencia la actitud de esas empresas de favorecer a Peña Nieto y perjudicar a López Obrador, Vázquez Mota y Otros Candidatos (Candidatos No Registrados + Votos Nulos).
Si se observa en la Figura 3 las estimaciones finales de los encuestadores –o la foto final, siguiendo la metáfora- se puede advertir cómo la mayor parte de las estimaciones de las casas encuestadoras estuvieron muy alejadas del resultado del cómputo distrital. De tal forma que de las once casas encuestadoras, cuatro de las estimaciones estuvieron fuera de precisión. La probabilidad que de 11 estimaciones, 4 estén fuera de precisión, es de una posibilidad en 694, de manera conservadora; de manera estricta sería una posibilidad en 9,261.
En un anterior artículo (se puede consultar aquí), se establecía que las estimaciones de una encuesta electoral deben de satisfacer dos principios básicos: (I) Los sesgos o desviaciones de las estimaciones tienen la misma probabilidad de ser positivos o negativos (propiedad de simetría) y, (II) Es más probable observar sesgos pequeños que grandes. Si se observa la Figura 3, se tiene que las estimaciones finales (puntos rojos), violan estos dos principios.
Las casas encuestadoras han inaugurado un subgénero de la ficción científica, que pudiera ser llamada, ficción estadística. Mediante ésta, hacen sinergia con los medios de “comunicación”, para contarnos una historia que está muy alejada de la realidad y que la distorsiona. Todo ello con el fin de imponer un candidato y, con ello, las reformas que, según ellos, necesita México (o más bien los insaciables poderes fácticos y los inversionistas extranjeros).
La compra del voto mediante las tarjetas Monex y Soriana, llevada a cabo por el PRI, evidencia de otra manera la actuación mayoritaria de las casas encuestadoras. La compra del voto se realizó porque hubo necesidad de ello (son deshonestos pero no tontos), es decir, de no haberse dado este hecho, probablemente Peña Nieto hubiese perdido la contienda. Lo cual contradice las estimaciones de la mayoría de las casas encuestadoras para Peña Nieto.
¿Le parecen sorprendentes estos resultados? Posiblemente no, pero al menos le proporcionan la base de un análisis estructurado y sólido para acompañar su intuición. ¡Bienvenido a la “democracia”!
Como se va haciendo costumbre, un especial agradecimiento a Daniel González Sepúlveda, por la revisión de este escrito, así como por sus correcciones y aportaciones al mismo.
“La democracia es un peligro para cualquier grupo en el poder.”
Noam Chomsky
Macario Hernández Garza.
Continuamos con la cuarta parte del análisis de las estimaciones de las casas encuestadoras en las elecciones del 2012 en México. Ahora con el análisis de las estimaciones para Enrique Peña Nieto. Con base a los resultados recopilados por ADNPolítico y publicados en su sitio de internet, en la liga: www.adnpolitico.com/encuestas. Como se ha comentado, a estas estimaciones se le añadieron las de Indermerc-Harris, las cuales se tomaron de los reportes entregados por esta encuestadora al IFE.
Análisis de las estimaciones de Enrique Peña Nieto.
El 11 de mayo de 2012, Peña Nieto tuvo su segundo día negro en su lucha por la presidencia en su visita a la Universidad Iberoamericana Campus Ciudad de México. Como se recordará, Peña Nieto terminó encerrado en un baño de mujeres, ante la indignación de los estudiantes, al justificar el uso de la violencia en Atenco durante su gobierno en el estado de México. Su primer día negro lo tuvo el 3 de diciembre de 2011, en la Feria Internacional del Libro de Guadalajara, al no haber podido responder la pregunta de los tres libros que habían marcado su vida, y confundir a Enrique Krauze con Carlos Fuentes.
La curva de estimaciones de todas las casas encuestadoras (estimaciones juntas o agregadas).

Figura 1
En la Figura 1 se muestran las estimaciones de las casas encuestadoras para Enrique Peña Nieto (EPN), así como la curva de promedios móviles de estas estimaciones. Cada estimación de la curva de promedios móviles se construyó, en cada fecha, con las últimas siete estimaciones para EPN (la curva de promedios móviles es la más gruesa y, la más delgada, es la curva formada por las estimaciones puntuales). La curva de promedios móviles muestra la tendencia en la preferencia electoral efectiva.
En esta figura se puede apreciar cómo, de un día para otro, se dan cambios en las estimaciones para EPN, de casi 10 puntos porcentuales, lo cual es una inconsistencia muy notable. Por ejemplo, el 27 de marzo, Demotecnia reportó 38.90 de preferencia electoral; Gea-Isa tuvo para este mismo candidato 48.1 el 28 de Marzo, una diferencia de 9.2 puntos porcentuales.
El 13 de mayo, dos días después de la debacle de Peña Nieto en la Universidad Iberoamericana, Demotecnia presentó su reporte, dando para EPN una estimación de 39.0 puntos porcentuales –estimación muy parecida a la del 27 marzo de esta misma casa encuestadora para EPN- La estimación de Demotecnia parece haber creado nerviosismo, a sólo dos días del desafortunado evento en la Iberoamericana, por lo que ocurrió a continuación.
El 14 de mayo, un día después de los resultados de Demotecnia, aparecen estimaciones de Indermerc-Harris dando una preferencia electoral efectiva de 50.0 para EPN (11 puntos por encima de la estimación de Demotecnia y 6 puntos por encima de la estimación que Gea-Isa reportó ese mismo día). Tratando de mandar, probablemente, la señal de que no pasaba nada, que la aparición de EPN en la Iberoamericana no le había afectado. Cabe señalar que esta fue la primera “encuesta”, o supuesta encuesta, de Indermerc-Harris; y da la impresión de que fue en respuesta a los resultados de Demotecnia del 13 de mayo. Tal vez no se atrevieron a usar a Gea-Isa porque sus estimaciones ya estaban demasiado cuestionadas, y usaron a otro “encuestador”, con una imagen no tan desgastada en esos momentos.
El 27 de mayo, Reforma dio a conocer los resultados de su encuesta. La preferencia electoral que Reforma reportó para EPN fue 38.0 puntos porcentuales, la más baja de todas las reportadas por las casas encuestadoras durante la campaña electoral. Un día después, se dieron a conocer los resultados de Indermerc-Harris, su estimación de preferencia electoral para EPN fue de 49.5 (11.5 puntos por encima de Reforma y 4.4 puntos más que Gea-Isa).
El 24 de junio, Demotecnia presenta resultados de una encuesta donde EPN tiene un 40.2 de preferencia electoral. El 25 de junio aparecen resultados de Indermerc-Harris donde EPN alcanza 47.2 puntos porcentuales de preferencia electoral.
Luego, de cuatro encuestas reportadas por Indermerc-Harris, tres de éstas aparecen un día después de resultados de casas encuestadoras en las que EPN tuvo las preferencias electorales más bajas en la campaña electoral (estimaciones muy bajas pero que estuvieron muy cerca del resultado del cómputo distrital para EPN, como fue el caso ya relatado de Demotecnia en dos ocasiones y Reforma en una). Lo mencionado en estos cinco últimos párrafos se puede apreciar en las Figuras 1 y 2. Las situaciones antes comentadas, hacen dudar de la autenticidad de los resultados de Indermerc-Harris.
Un papel similar al que jugó Indermerc-Harris en 2012, lo jugó Marketing Político en 2006. Marketing Político apareció, también, en la recta final de la campaña y en las encuestas de salida y conteos rápidos, dando siempre las estimaciones mayores para Felipe Calderón.
En la Figura 1 se tienen las estimaciones de todas las casas encuestadoras para EPN, lo cual da un cierto anonimato para los encuestadores, a menos que mostremos explícitamente algunas estimaciones con anotaciones, como ahí se hace.
Las curvas de estimaciones por casa encuestadora (estimaciones por separado o desagregadas).
En la Figura 2, se presentan las estimaciones de los encuestadores por separado o desagregadas, es decir, se grafican las estimaciones de cada encuestador en una curva individual. Esto hace que se muestre la conducta de las estimaciones de cada encuestadora, y con ello, salgan del anonimato; y muestren su actuación individual. Se muestra en esta figura, como antes, la curva de promedios móviles de las últimas 7 estimaciones.
La última estimación de promedio móvil producida por las últimas 7 estimaciones de las casas encuestadoras en junio de 2012, está basado en un tamaño de muestra de 7950 (la suma de tamaño de muestra de las últimas 7 encuestas). Una estimación basada en una muestra de este tamaño debería tener un error máximo muy cercano al 1.0%. La última estimación de promedio móvil para EPN fue de 44.07, lo cual da un error de 5.86 que resulta de la diferencia entre 44.07 y 38.21, que es casi seis veces el error máximo de 1.0%, como se puede apreciar en la Figura 2. Y este error tan grande resulta de las estimaciones con sesgos exageradamente grandes de la mayoría de las casas encuestadoras para EPN. Resulta contradictorio que Demotecnia con un tamaño de muestra de 1500, tenga un error 1.99 y que el error del último promedio móvil con un tamaño de muestra total de 7950 resulte en un error de 5.86 ¿El mundo al revés? No, simple manipulación de las estimaciones.

Figura 2
En la Figura 2, se puede observar cómo la conducta de la curva de las estimaciones de Demotecnia, es tan diferente a las de las restantes casas encuestadoras. Y como la estimación de Demotecnia fue la más precisa, y con una variabilidad pequeña a través de la campaña electoral, por lo que podemos pensar que la historia contada por las estimaciones por Demotecnia es la más apegada a la realidad, y que las estimaciones de las restantes casas encuestadoras obedecieron a un libreto preestablecido.
Por nivel de manipulación favorable a EPN se tiene, en primer lugar, a Indermerc-Harris y Gea-Isa (le llamaré Grupo I). Durante el corto lapso en que realizó encuestas Indermerc-Harris, siempre tuvo las estimaciones más altas para EPN –una conducta totalmente sistemática-. Además, mostraron una total falta de imaginación en sus estimaciones ¿o sería mejor decir en sus manipulaciones? Su primera estimación fue de 50.0 (un número entero, un valor poco probable de conseguirse), la siguiente estimación fue de 49.5 (decremento de 0.5), la tercera estimación 49.0 (decremento de 0.5). Además de que sus estimaciones, por los días en que aparecieron, más bien parecen reacciones publicitarias a las estimaciones de Demotecnia y Reforma.
Se puede notar que la curva de Gea-Isa tiene subidas y bajadas inverosímiles, si la comparamos con la curva de Demotecnia. Lo cual nos muestra que estos cambios en las estimaciones obedecían más a los caprichos (¿o acaso negociaciones?) de Ricardo de la Peña, Jesús Reyes Heroles y sus patrocinadores –los abiertos y los encubiertos- más que a los cambios en las preferencias electorales de EPN.
En segundo lugar, se observa un grupo de encuestadores, más o menos compacto, a través de la campaña electoral. Este grupo formado por: Parametría, Buendía & Laredo, BGC, Mitofsky y Con Estadística (Grupo II). Este grupo, se puede decir, manipularon consistentemente sus estimaciones.
En tercer lugar se encuentran el grupo de encuestadoras formado por: Reforma, Covarrubias e Ipsos-Bimsa (Grupo III). Observando en la Figura 2, se tiene que Ipsos-Bimsa, Covarrubias y Reforma, tuvieron algunas estimaciones parecidas a la de las encuestadoras del Grupo II. El caso más extremo fue el de Ipsos-Bimsa, en el cual únicamente la estimación final salió del Grupo II de encuestadores.
Finalmente se tiene a la encuestadora Demotecnia (grupo IV), la cual tuvo la estimación más cercana al resultado final de EPN y, además, tuvo la variabilidad más pequeña en sus estimaciones. Debido a lo anterior, Demotecnia tuvo el mejor desempeño en cuanto a las estimaciones de Peña Nieto. O desde otro punto de vista, fue la encuestadora que manipuló en menor grado sus estimaciones.
Se debe considerar que el resultado del cómputo distrital de EPN tiene incorporado algunos puntos porcentuales producto de la compra del voto con las tarjetas Monex y Soriana. Luego, si no se hubiera presentado la compra del voto, no sólo se hubiese comprometido el triunfo de Peña Nieto, sino que el desempeño de las encuestadoras, ya de por sí desastroso, hubiese sido todavía peor.
Gráfico de rangos de variabilidad y estimación final por casa encuestadora.

Figura 3
La Figura 3 muestra, desde otra óptica, la actuación de las encuestadoras en las estimaciones para EPN. Las líneas horizontales representan el rango de variabilidad de las estimaciones. Los puntos rojos representan la última estimación reportada y, finalmente, la línea vertical punteada representa el resultado del cómputo distrital para EPN. A la derecha de cada línea horizontal, aparecen dos números: el primero representa el rango de variabilidad y, el segundo, el sesgo final, es decir la diferencia entre la última estimación y el resultado del cómputo distrital.
A los encuestadores les gusta utilizar la metáfora de que la estimación de preferencia electoral para un candidato dado y, en un momento determinado, es una fotografía de ese momento, y creo es una metáfora afortunada. Sin embargo, como antes se comentó, en ocasiones, de un día para otro, hay estimaciones de encuestadores, que tienen diferencias mayores a 10 puntos porcentuales –sin haber un suceso político que explique este cambio- lo cual indica que alguna de estas dos fotografías –aplicando la metáfora- está fotoshopeada. O bien, las dos lo están, pero uno de ellos exageró en la alteración de la foto.
Otra metáfora sería que, si una estimación representa una fotografía del momento, la serie de las estimaciones de cada encuestador representa una película de cómo se movieron las preferencias electorales durante la campaña electoral para un candidato dado.
Viendo de esta manera a los rangos de variabilidad de las diferentes casas encuestadoras, la película de Demotecnia es muy diferente de las películas de los demás encuestadores, ya que su rango de variabilidad es de sólo 1.30. El rango de Demotecnia también está más cercano al resultado final, lo que hace pensar que los restantes encuestadores estuvieron alterando, en forma considerable, sus estimaciones para favorecer a Peña Nieto.
Hay que considerar la influencia de la compra del voto, mediante las tarjetas Monex y Soriana, en el resultado electoral de EPN. Es decir, no les bastó con el enorme dispendio de recursos a favor de EPN en la campaña electoral; la cargada de la mayoría de los medios de comunicación a su favor –Jesús Cantú Escalante, académico e investigador del Instituto Tecnológico y de Estudios Superiores de Monterrey y ex Consejero General del IFE, realizó un estudio al respecto, puede consultar un artículo sobre el mismo en http://www.animalpolitico.com/2013/06/las-televisoras-vulneraron-la-equidad-en-la-eleccion-presidencial-estudio/#axzz2YfzNBlvv,ni la utilización, a manera de spots, de las estimaciones de los encuestadores artificialmente alteradas a favor de EPN. Aun así, tuvieron que utilizar la compra del voto, porque con todo lo anterior no les fue suficiente.
Lo anterior es una prueba adicional de que las estimaciones de la mayoría de las casas encuestadoras estaban alteradas a favor de EPN. De otra forma ¿Para qué utilizar la compra del voto? ¡Si según las casas encuestadoras, Peña Nieto iba en caballo de hacienda a ganar las elecciones en 2012!
Si se observan las estimaciones finales de los encuestadores –o la foto final, siguiendo la metáfora- se puede advertir cómo la mayor parte de las estimaciones de las casas encuestadoras estuvieron muy alejadas del resultado del cómputo distrital. De tal forma que de las once casas encuestadoras, ocho de las estimaciones estuvieron fuera de precisión. La probabilidad que de 11 estimaciones, 8 estén fuera de precisión, es de una posibilidad en 180 millones, de manera conservadora; de manera estricta sería una posibilidad en 42 mil millones.
En un anterior artículo (se puede consultar aquí), se establecía que las estimaciones de una encuesta electoral deben de satisfacer dos principios básicos: (I) Los sesgos o desviaciones de las estimaciones tienen la misma probabilidad de ser positivos o negativos (propiedad de simetría) y, (II) Es más probable observar sesgos pequeños que grandes. Si se observa la Figura 3, se tiene que las estimaciones finales (puntos rojos), violan estos dos principios.
Como se ha visto, la actuación de las casas encuestadoras, en general, fue desastrosa. Pero lo fue, fundamentalmente, por la manipulación de las estimaciones, más que por las fallas técnicas –aunque dichas encuestadoras tienen fallas muy evidentes en la metodología que ellas mismas reportan–.
El papel de los encuestadores en las elecciones, ha sido el mismo que el de la mayoría de los medios de comunicación: presentar una realidad distorsionada.
La Unidad de Fiscalización del Instituto Federal Electoral (IFE) debió cargar a los gastos de campaña de Enrique Peña Nieto, los costos de las encuestas ya que, finalmente, estuvieron al servicio de este candidato.
En febrero de 2013 la Unidad de Fiscalización del IFE presentó un dictamen donde aplicaba un doble rasero, que raro ¿verdad? Por ejemplo: las cachuchas que se repartieron en la campaña de López Obrador se les asignó un costo de 16.30 pesos mientras que las repartidas en las campañas de Peña Nieto les fueron asignadas un costo de 20 centavos. Dicho dictamen traía otros absurdos como que el uso del estadio Azteca en el cierre de campaña de Peña Nieto costó solamente 46 mil 845 pesos, pero no se reporta renta del inmueble ni su factura.
Era tan absurdo dicho dictamen sobre ingresos y gastos de los partidos políticos en las campañas presidenciales de 2012, que los consejeros del IFE decidieron regresarlo y posponer su discusión hasta julio de 2013.
Lo dicho, cualquier aspecto que se revise en las elecciones presidenciales, se puede ver que estas se llevan a cabo con los dados cargados para favorecer a uno de los candidatos.
Un especial agradecimiento a Daniel González Sepúlveda por la revisión de este escrito, así como por sus correcciones y aportaciones al mismo.
Por Macario Hernández Garza.
Se ha comentado en un post publicado en Colloqui el 2 de mayo del presente año (el cual se puede consultar aquí), que ADNPolítico estuvo recopilando en su sitio de internet, las estimaciones de preferencia bruta y efectiva de las casas encuestadoras para los candidatos a la elección presidencial de 2012 en México (a estas estimaciones se le añadieron las de Indermerc-Harris, las cuales fueron tomadas de los reportes entregados por esa casa encuestadora al IFE).

Figura 1
Se construyó un gráfico de series de tiempo, en cuyo eje vertical se tienen las estimaciones de preferencia neta reportadas por las casas encuestadoras y, en el eje horizontal, la fecha de terminación del trabajo de campo en el levantamiento de la encuesta. El gráfico se muestra en la Figura 1.
A este gráfico se le añadió también, para cada candidato, una curva de promedios móviles. Cada estimación de la curva de promedios móviles se construyó en cada fecha con las últimas siete estimaciones para un candidato dado (la curva de promedios móviles es la línea más gruesa, y la más delgada es la curva formada por las estimaciones). La curva de promedios móviles nos muestra las tendencias en la preferencia efectiva para cada candidato.
A la derecha de esa figura se muestran, para cada candidato, los resultados del cómputo distrital del IFE.
En estadística se le llama valor atípico[1] (en inglés se le llama outlier) a un valor que es muy distante del resto de los datos o de su patrón de distribución.

Figura 2
La Figura 2, fue tomada del libro: The Virtual Display of Cuantitative Information, de Edward Tufte, Segunda Edición. En esa figura se muestra como el Punto A es un valor atípico (outlier) en el plano bidimensional.
Un valor atípico puede presentarse por errores de medición o estimación, errores de captura, mezcla de estimaciones de dos poblaciones diferentes, presentación de resultados poco probables y, agregaré otra causa: por la manipulación de las estimaciones.
Algunos sinónimos para atípico son: irregular, extraño, raro e infrecuente. Algunos antónimos para atípico son: típico y habitual.
Luego, un valor atípico es un valor que se aparta o es muy diferente del patrón de datos, tiene una conducta singular o rara. Por lo antes establecido, los valores atípicos deben estar en minoría en relación al conjunto restante y mayoritario de los datos.
Lo expresado anteriormente acerca de los valores atípicos –en cuanto a que están en minoría– se cumple cuando las mediciones o estimaciones fueron hechas de manera honesta y, quienes las realizaron, tienen la capacidad técnica adecuada para la obtención de las mismas.
De haber deshonestidad en el cálculo de la mayoría de las estimaciones, se puede presentar el escenario de que los aparentes valores atípicos sean los más cercanos a la realidad, y la mayoría de los valores sean los más alejados de ésta, por haber sido alterados a propósito.
En la Figura 3 –continuación de la Figura 2- se han agregado líneas horizontales de referencia, que pasan por el punto que representa el resultado del cómputo distrital para cada candidato. También se muestran algunos de los aparentes valores atípicos para las estimaciones de Peña Nieto, en las fechas en que ocurrieron éstos.
Se pueden apreciar en esa misma Figura 3 algunas situaciones raras o singulares. Una de ellas es que durante el mes de junio, casi todas las estimaciones para Peña Nieto (salvo la del 27 de mayo de Reforma) fueron mayores al resultado del cómputo distrital del IFE para dicho candidato (sesgos positivos). Incluso la última estimación para Peña Nieto, que corresponde a GEA-ISA, tiene un sesgo a favor de este candidato de 8.69 puntos porcentuales.
La curva de promedios móviles de Peña Nieto, siempre estuvo por encima de la estimación del cómputo distrital para este candidato.
Para López Obrador se tiene la situación contraria. Casi todas las estimaciones, salvo tres, siempre estuvieron por debajo del resultado del cómputo distrital; además, la curva de promedios móviles siempre estuvo por debajo del resultado del cómputo distrital del IFE para este candidato.

Figura 3
Se puede observar en la Figura 3, como Demotecnia y Reforma tuvieron estimaciones aparentemente atípicas, las cuales se encontraron muy cerca del resultado del cómputo distrital del IFE para Peña Nieto; particularmente las del 27 de marzo (Demotecnia), 13 de mayo (Demotecnia) y 27 de mayo (Reforma).
Demotecnia realizó solamente tres encuestas, y dos de ellas están bastante cercanas al resultado del cómputo distrital para Peña Nieto, lo mismo ocurre con la estimación de Reforma para el 27 de mayo. Lo anterior sugiere que las fluctuaciones mostradas por los otros encuestadores para Peña Nieto eran ficticias.

Figura 4
En la Figura 4 se ha agregado un rectángulo con líneas punteadas, el cual encierra estimaciones aparentemente atípicas, si se considera el total de las estimaciones. El rectángulo encierra a las estimaciones que están alejadas 2.5 puntos porcentuales o menos del resultado del cómputo distrital para Peña Nieto, que fue 38.21 puntos porcentuales. Las estimaciones aparentemente atípicas de las casas encuestadoras para Peña Nieto fueron las siguientes: 27 marzo, Demotencia 38.9 puntos porcentuales; 13 de mayo, Demotecnia 39; 16 de mayo, Covarrubias 40; 27 de mayo, Reforma 38; 24 de junio, Demotecnia 40.2.
La paradoja de paradojas es que, las estimaciones y el resultado oficial del cómputo distrital del IFE para Peña Nieto, los cuales están encerradas en el rectángulo de líneas punteadas son todos valores atípicos en relación a la mayoría de las estimaciones. Entonces resulta ser que, en particular, el valor oficial del resultado del cómputo distrital de Peña Nieto resulta ser también un valor atípico, ¡cuándo este valor es el que están estimando las mediciones de las casas encuestadoras!
De las cinco estimaciones más cercanas a Peña Nieto, en el lapso de enero a junio de 2012, tres fueron de Demotecnia de María de las Heras (véase la Figura 4), por lo que, como antes se ha comentado, se puede suponer que las estimaciones de Peña Nieto no tuvieron tanta fluctuación, como lo quisieron hacer creer la mayoría de las casas encuestadoras, entre ellas, principalmente, Gea-Isa de Ricardo de la Peña y Jesús Reyes Heroles.
En un programa de televisión donde se discutían las estimaciones de las encuestas, el conductor preguntaba por qué las estimaciones de Reforma, correspondientes al día 27 de mayo de 2012, eran tan diferentes a las de los otros encuestadores, a lo que Roy Campos, de Consulta Mitofsky, respondía que las estimaciones de la mayoría de los encuestadores eran consistentes, por lo cual Reforma debía explicar el porqué de la diferencia o inconsistencia. Se daba por hecho, mañosamente, que si las estimaciones de la mayoría de los encuestadores eran consistentes entonces eran acertadas. En realidad si las estimaciones de la mayoría de los encuestadores son consistentes puede ser que: (1) estén midiendo bien en forma consistente (2) estén midiendo consistentemente mal (3) que estén manipulando de manera consistente sus estimaciones.
Si se comparan las últimas estimaciones de las casas encuestadoras con el resultado del cómputo distrital del IFE, sugiere que la mayoría de los encuestadores estuvieron manipulando consistentemente sus estimaciones.
Esto es, si camina como pato, tiene pico de pato y cola de pato, ¿Qué cree usted que sea?
Un especial agradecimiento a Daniel González Sepúlveda por la revisión de este escrito, así como por sus correcciones y aportaciones al mismo.
[1] Según la Real Academia Española de la Lengua atípico o atípica significa: 1. adj. Que por sus caracteres se aparta de los modelos representativos o de los tipos conocidos.
“En ningún momento de la historia del mundo, la mentira organizada se ha practicado con menos vergüenza, o por lo menos, gracias a la tecnología moderna, más eficientemente o a una escala tan amplia, que por los dictados políticos y económicos de este siglo.”
Aldous Huxley
Por Macario Hernández Garza.
ADN Político estuvo recopilando en su sitio de internet: www.adnpolitico.com/encuestas, las estimaciones de las casas encuestadoras para los candidatos a la elección presidencial de 2012. Se bajó de internet la base de datos, para hacer un análisis de los mismos. A los datos de ADNPolítico se le agregaron los datos de Indermerc, los cuales fueron tomados de los reportes entregados al IFE, y aunque parezca difícil, sus sesgos para Peña Nieto son favorables y mayores a los de GEA-ISA, que ya es mucho decir.
GEA-ISA realizó –o dijo realizar- 102 encuestas de las 186 reportadas por ADNPolítico, lo cual representa el 54.84% del total de encuestas, el patrocinador oficial de estas encuestas fue Milenio. El segundo lugar, respecto al número de encuestas, fue para Consulta Mitofsky con 17, lo cual representa el 9.14% del total, y quien en los últimos años ha trabajado para Televisa y en los programas de esa televisora estuvo presentando sus resultados; según los reportes de Mitofsky la casa encuestadora fue la patrocinadora de sus propias encuestas, situación que me cuesta creer. Se tiene luego que, entre GEA-ISA y Mitofsky realizaron el 63.98% de las encuestas, además de que las encuestas de estas dos casas fueron las más publicitadas en los medios de comunicación, debido a sus promotores abiertos u ocultos.

Figura 1
En un artículo publicado en Colloqui el 16 de agosto de 2012, y que se puede consultar en la siguiente liga, se establecía que dado que las estimaciones de una encuesta tiene una distribución normal, y con media la preferencia electoral del candidato, o bien, la votación del mismo. Se debe cumplir que: (1) los sesgos -las desviaciones de las estimaciones respecto al resultado oficial del candidato- tienen la misma probabilidad de ser tanto positivos como negativos; y (2) es más probable observar sesgos pequeños que grandes.
Se puede observar en la Figura 1 cómo los sesgos de Peña Nieto son todos positivos contraviniendo el principio (1). Y todos son sesgos grandes, contraviniendo el principio (2), es decir, los encuestadores se “equivocaron” a favor de Peña Nieto. Algo parecido, aunque en sentido contrario, ocurre con los sesgos de Otros Candidatos, formado por (Candidatos no Registrados + Votos Nulos); la totalidad de los sesgos correspondientes son negativos e iguales (carencia absoluta de aleatoriedad y, por tanto, hay una intencionalidad en los mismos), además de que no se satisfacen los principios (1) y (2) antes señalados, los encuestadores se “equivocaron” afectando a Candidatos No registrados y Votos Nulos, al fin de cuentas, ¿quién defenderá a éstos? Y así podemos seguir con los otros candidatos hay, en general, violaciones a uno u otro principio, con lo cual queda de manifiesto la falta a los principios estadísticos (1) y (2) antes mencionados.
Todas las casas encuestadoras tienen sesgos favorables hacia Peña Nieto y sesgos desfavorables e idénticos (lo cual es muy poco probable de ocurrir) para Otros Candidatos y casi todas las mismas tienen sesgos desfavorables hacia López Obrador y Vázquez Mota.
En las Figuras 1 y 2 las barras horizontales de color verde, son sesgos favorables al candidato, y las rojas son sesgos desfavorables.

Figura 2
En la Figura 2, se grafican los sesgos totales (suma de los sesgos en la última encuesta para cada candidato). Se puede apreciar cómo los únicos candidatos que tienen sesgos totales favorables son Enrique Peña Nieto y Gabriel Quadri; los únicos que tienen sesgos totales negativos son los restantes candidatos.
En la Figura 2 se aprecia que, en general, tomando a las casas encuestadoras como un sistema de medición, es un sistema de medición absolutamente sesgado, con sesgo total favorable en primer lugar hacia Enrique Peña Nieto (59.79) y luego a hacia Gabriel Quadri (8.22) y desfavorable, en primer lugar hacia Otros Candidatos (Candidatos no registrados y Votos Nulos) (-27.61), luego hacia Andrés Manuel López Obrador (-23.79) y finalmente, hacia Josefina Vázquez Mota (-15.81).
Sumando los tamaños de muestras reportados por las once casas encuestadoras, se tiene que, en conjunto, las once casas encuestadoras entrevistaron a 15,110 ciudadanos. Cuando se tiene una estimación de preferencia electoral basada en este tamaño de muestra se debe tener un error cercano a ±0.87 puntos porcentuales como límite aproximadamente. Resulta entonces absurdo que el error o sesgo promedio de Peña Nieto sea de 5.44 puntos porcentuales, como se puede revisar en el renglón inferior de la Figura 1. Lo mismo ocurre para los sesgos de Obrador, Vázquez Mota y Otros Candidatos, sólo que en sus casos los sesgos son negativos.
En las Figura 3 y 4 se muestran los resultados de un estudio de simulación correspondiente a las Figuras 1 y 2. En el caso de las Figuras 3 y 4, las estimaciones, y de aquí los sesgos, fueron obtenidos mediante la técnica de simulación asumiendo que las preferencias electorales de los candidatos fueron los resultados oficiales de los cómputos distritales del IFE, y las precisiones fueron las reportadas por las casas encuestadoras.
Se puede advertir cómo, en la Figura 3, los sesgos satisfacen los principios (1) y (2) antes señalados, es decir, hay un cierto balance en los sesgos positivos (favorables) de color verde y los sesgos negativos (desfavorables) de color rojo, para los diferentes candidatos. Además, son más frecuentes los sesgos pequeños que los grandes. A diferencia de la Figura 1, donde no ocurre esto y, por tanto, se nota que hubo “mano negra”.

Figura 3
Asimismo se puede observar en la Figura 4 como los sesgos totales obtenidos mediante simulación son muy pequeños en comparación con los obtenidos por las casas encuestadoras y mostrados en la Figura 2. Esto ocurre concordando con el principio (1) que afirma que los sesgos tienen la misma probabilidad de ser tanto positivos como negativos, por lo cual hay una tendencia a anularse unos con otros, dando como resultado sesgos totales pequeños como los mostrados en la Figura 4.

Figura 4
Otra situación que llama la atención, es que 9 de las 11 de las encuestas son patrocinadas por medios de comunicación (Mitofsky con 17 encuestas e Ipsos-Bimsa con 7, afirman ser ellos mismos los patrocinadores de sus encuestas, lo cual es difícil de creer dado el costo de una encuesta nacional), lo que pone de manifiesto el papel que juegan los medios como aliados del poder. Actúan como un poder fáctico más. El filósofo Fernando Buen Abad ha señalado el papel de los medios de comunicación en América Latina, calificándola como una auténtica oligarquía mediática –aunque probablemente esto ocurra a nivel internacional-, afirma Buen Abad que la derecha Latinoamericana ha perdido las batallas ideológicas y han tenido que salir a su rescate los medios de comunicación. Este rescate, obviamente, no es gratuito, hay un entramado de intereses entre éstos. Recordemos cómo, en las elecciones de 2006, las estimaciones “equivocadas intencionalmente” de GEA-ISA a favor de Felipe Calderón, se tradujeron en la dirección de PEMEX para Federico Reyes Heroles y la dirección del CISEN para Guillermo Valdés Castellanos, ambos miembros de GEA.
En una videoconferencia llevada a cabo el 24 de febrero de 2013, Julian Assange ilustraba el papel primordial de los medios de comunicación para el estado, y por ende, su control sobre éstos (se puede consultar el video en la siguiente liga). Decía Assange que cuando un país extranjero ocupa otro país, controla tres áreas prioritarias: (a) las fuerzas militares y los cuerpos policíacos, (b) las fuentes de energía y (c) los medios de comunicación: radio, televisión y prensa. Lo anterior explica, de alguna forma, la importancia de los medios de comunicación para el Estado y por ende, la alianza de los encuestadores, medios de comunicación, los poderes fácticos y el régimen.
Como un ejemplo del entramado que hay de los medios de comunicación y los grandes consorcios, políticos y algunos intelectuales, se tiene que en el consejo directivo de Televisa se encuentran: Pedro Aspe Armella (ex secretario de Hacienda), Alberto Bailléres González, José Antonio Fernández Carbajal (Coca Cola Femsa), Carlos Fernández González (Grupo Modelo), Claudio X. González Laporte (Kimberly-Clark de México), Germán Larrea Mota Velasco (Grupo México), Roberto Hernández Ramírez (Banco de México), Enrique Krauze Kleinbort (Editorial Clío), y Eduardo Tricio Haro (Grupo Industrial Lala), entre otros.
Los sesgos favorables de las casas encuestadoras hacia Enrique Peña Nieto, se correspondieron, o estuvieron alineados, con el sesgo en las líneas editoriales de Televisa, Milenio, El Universal, y la mayor parte de los medios de comunicación. En las estimaciones de las casas encuestadoras y, por tanto, en los sesgos, el azar estuvo ausente, porque un componente de las estimaciones de las casas encuestadoras estuvo determinado, seguramente, desde las oficinas de estos consorcios mediáticos y en las del PRI.
Del análisis de la última encuesta se tiene que los encuestadores, así como los medios de comunicación que la patrocinaron, tuvieron una actuación absolutamente parcial y favorable hacia Enrique Peña Nieto. Y por si esto fuera poco, los encuestadores contaron con la defensa del consejero presidente del IFE: Leonardo Valdés Zurita. Con ello Valdés Zurita dio una muestra de una ignorancia absoluta sobre la materia, aunque éste afirma saber de encuestas, o bien, de una complicidad que no se puede tolerar en un árbitro que debe ser neutral. “Cosas veredes…”
Agradezco a mi amigo y socio Daniel González Sepúlveda, por la revisión y observaciones hechas a este escrito.
Macario Hernández Garza
El Blog lo he tenido muy olvidado, por diferentes motivos. Intentaré reactivarlo, para ello, empezaré a publicar algunos artículos acerca de las elecciones presidenciales en México, que antes publiqué en el sitio Colloqui.org.
Algunos principios que satisfacen las estimaciones de encuestas probabilísticas
Con el fin de ilustrar algunos principios estadísticos básicos que cumplen las estimaciones de preferencia electoral, obtenidas mediante encuestas probabilísticas, se realizó una simulación computacional de la estimación de la preferencia electoral de un candidato mediante una encuesta. Se asumió que la preferencia electoral es de 38.21%. La estimación de la preferencia electoral simulando una encuesta se repitió 3,000 ocasiones. Para efectos de ilustración, se hicieron corridas de 30 estimaciones, y estas corridas de 30 estimaciones se repitieron 100 veces, para dar el total de 3,000 estimaciones.
Como se verá, las estimaciones de una encuesta electoral tienen un comportamiento aleatorio, siguen ciertos principios estadísticos, éstas no tienen un comportamiento caótico, como nos quieren hacer creer los encuestadores “reconocidos”.
Figura 1
En el gráfico inferior derecho se tiene el histograma de las 3,000 estimaciones simuladas de la preferencia electoral del candidato. La línea verde corta en el eje x el valor de la preferencia electoral del candidato: 38.21%; la línea roja de la izquierda corta al eje x en Preferencia Electoral – Error = 38.21% – 3.1% = 35.11%; de la misma forma la línea roja de la derecha corta el eje x en Preferencia Electoral + Error = 38.21% + 3.1 = 41.31%. Las estimaciones obtenidas por simulación que caigan entre estas dos líneas rojas son estimaciones que caen dentro de precisión, y por el contrario, las que caigan fuera de estas líneas rojas estarán fuera de precisión.
Del histograma anterior se tiene que las estimaciones de preferencia electoral, obtenidas mediante encuestas probabilísticas, cumplen tres principios:
- Las desviaciones de las estimaciones respecto de la preferencia electoral tienen la misma probabilidad de ser tanto positivas como negativas, es decir, las estimaciones pueden ser mayores que la preferencia electoral, o menores que ésta con la misma probabilidad.
- Es más probable observar desviaciones pequeñas que desviaciones grandes.
- Las estimaciones tienen una distribución normal.
En la gráfica superior de la Figura 1, se tiene la última corrida de 30 estimaciones. Cada estimación está representada por un punto en el centro del intervalo de confianza. La línea central, de color verde, representa la estimación de la preferencia electoral del candidato, que es 38.21%. Las líneas rojas representan los límites de precisión[1], la línea límite superior de precisión tiene el valor de: Preferencia Electoral + Error = 38.21% + 3.1% = 41.31%; mientras que la línea límite inferior de precisión tiene el valor de: Preferencia Electoral – Error = 38.21% – 3.1% = 35.11%.
En esta gráfica se puede observar como por la distribución normal de las estimaciones, es más probable observar estimaciones cerca de la preferencia electoral, que lejos de ésta. Las estimaciones que están fuera de precisión quedarán fuera de las líneas de color rojo, y cuando esto suceda, su intervalo de confianza correspondiente no contendrá al valor de la preferencia electoral, como se puede ver en esa gráfica. Esta gráfica superior tiene las estimaciones de la repetición 100, de las últimas 30 estimaciones, como se ve, hay cuatro estimaciones fuera de precisión y, por lo tanto, 26 estimaciones dentro de precisión, entonces la fracción de estimaciones dentro de precisión es 26/30 = 0.8666. Puesto en porcentaje, el 86.67% de las últimas 30 estimaciones están dentro de precisión, o bien, se puede decir que, el nivel de confianza observado de las últimas 30 estimaciones es de 86.67%.
En la gráfica de la parte inferior izquierda de la Figura 1, se muestran las confianzas observadas para cada una de las repeticiones de 30 estimaciones, la línea punteada negra representa el promedio del nivel de confianza observado en las 100 repeticiones de 30 estimaciones el cual es 95.43%, un valor bastante cercano al nivel de confianza teórico del 95%, representado por la línea azul en ese gráfico.
Con lo anterior se verifica lo antes comentado: las estimaciones de las preferencias electorales obtenidas mediante encuestas, tienen una variabilidad aleatoria que satisface principios estadísticos.
Una primera aproximación a las estimaciones de las casas encuestadoras
En este análisis se revisará el conjunto de las últimas estimaciones de las casas encuestadoras para los candidatos a la presidencia en las elecciones de 2012 en México. La información de las Tablas 1 y 2, fue obtenida de internet, de los sitios de las propias casas encuestadoras o de los sitios de internet de los patrocinadores de las encuestas.
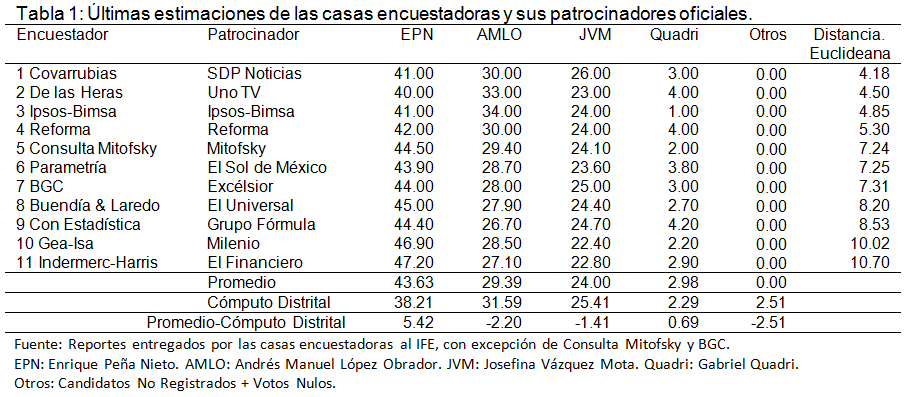
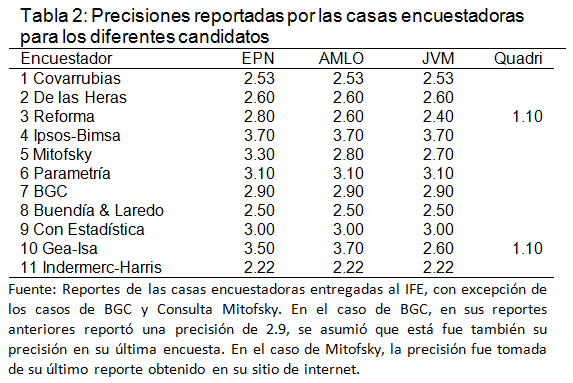
De la Tabla 1 se tiene que, según los reportes de Ipsos-Bimsa y Consulta Mitofsky, estas casas encuestadoras son sus propios patrocinadores, algo difícil de creer dado el costo de una encuesta nacional. También se tiene falta de aleatoriedad en algunas estimaciones, dados algunos empates inverosímiles para Peña Nieto: Covarrubias y Reforma: 41.0; Ipsos-Bimsa y El Universal: 41.20.
Otro aspecto importante a observar en la Tabla 1 es que la mayor parte de los encuestadores tienen 0% para Otros Candidatos, que normalmente correspondería a Candidatos No Registrados y Votos Nulos. Esto lo consiguen los encuestadores diseñando el cuestionario de la encuesta de tal forma que sólo preguntan por qué candidato de los registrados votarán, a sabiendas de que algunos ciudadanos votan por Candidatos No Registrados, o bien, anulan el voto por voluntad propia. Este no es un error de las casas encuestadoras, es una forma de tomar los puntos porcentuales correspondientes a Candidatos No Registrados y asignárselos algún candidato particular, el cual resultaría favorecido.
En la Figura 2, se muestran las estimaciones de las casas encuestadoras para los candidatos, así como los resultados de los cómputos distritales para cada candidato (mediante una línea roja continua). También se muestran los promedios de las estimaciones de las casas encuestadoras para cada candidato (mediante una línea roja punteada).
Se puede apreciar, en la misma Figura 2, como todas las casas encuestadoras, se “equivocaron” a favor del candidato que, presuntamente, más gastó en campaña. Es decir, todas las estimaciones para este candidato fueron mayores que el resultado del cómputo distrital; en otras palabras, cada casa encuestadora tuvo un sesgo positivo para este candidato. Otro aspecto importante es que las estimaciones para Peña Nieto muestran una estratificación, como se puede observar, se forman tres grupos de estimaciones.
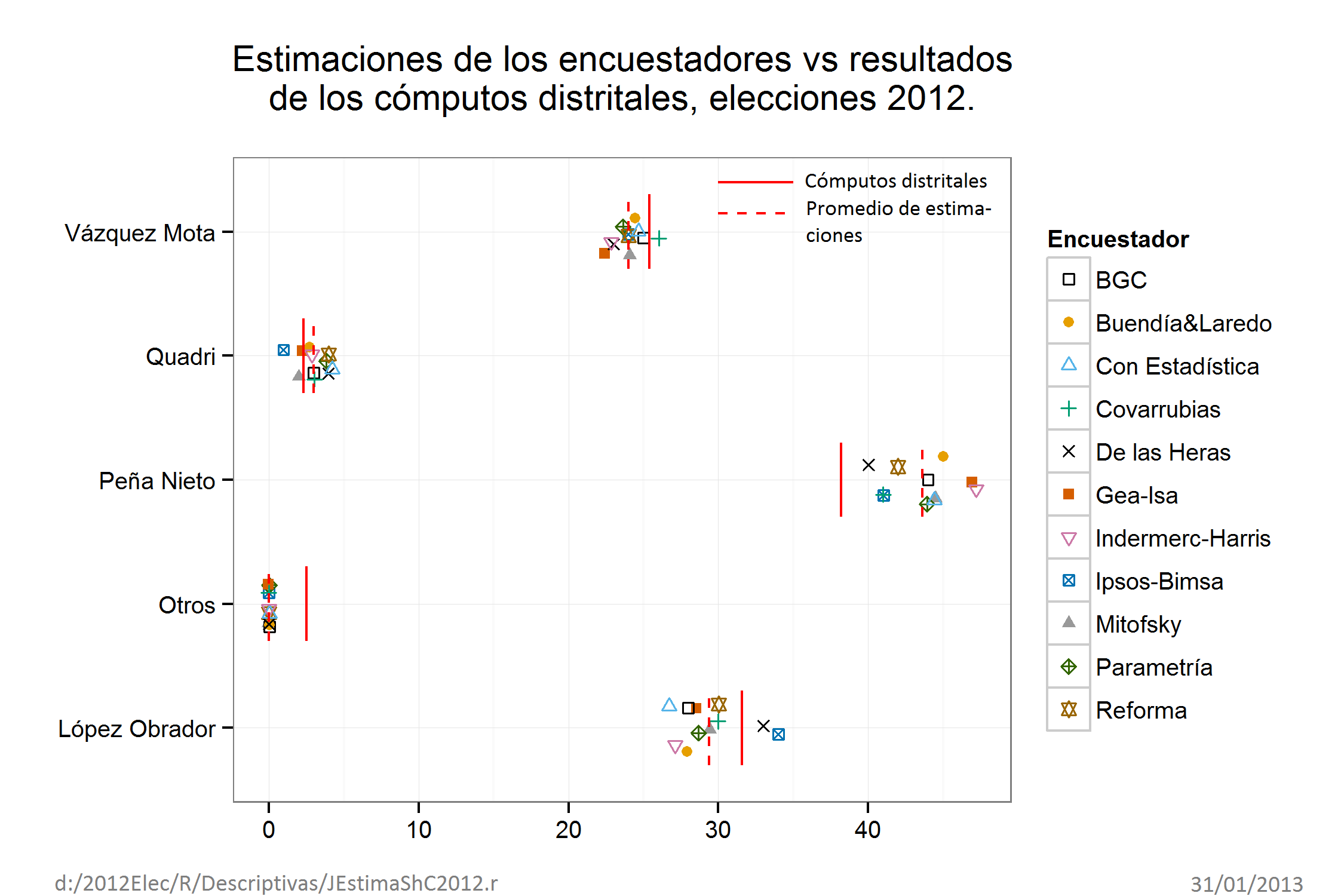
Figura 2
Para tener una idea de la magnitud de los sesgos, si se realiza la diferencia Promedio de Estimaciones menos el resultado del Cómputo Distrital para cada candidato (estos valores se encuentran en el último renglón de la Tabla 1) se tendría: Peña Nieto: 5.02; Quadri: 0.80; Otros Candidatos: -0.85; Vázquez Mota: -1.85 y López Obrador: -3.12. Es decir, las “equivocaciones” de las casas encuestadoras hicieron que el mayor beneficiado de ello fuera Peña Nieto con un sesgo a favor de 5.02, y el más perjudicado fuera López Obrador con un sesgo de -3.12.
Las estimaciones de las casas encuestadoras mostradas en la Figura 2 violan los principios estadísticos que antes se habían establecido, ya que estas deberían tener una distribución normal y, por lo tanto, las estimaciones deben distribuirse en forma simétrica alrededor del valor que están estimando, en este caso, el resultado del cómputo distrital; y violan también el principio de que es más probable observar desviaciones pequeñas de las estimaciones hacia el valor estimado –Cómputo Distrital- que observar desviaciones grandes.
Estimaciones obtenidas mediante simulación
Se generaron estimaciones mediante simulación asumiendo que las preferencias electorales de los candidatos son los resultados oficiales de los cómputos distritales, los cuales se muestran en el penúltimo renglón de la Tabla 1. No se generaron estimaciones para Quadri y Otros candidatos debido a que no se tienen errores muestrales o precisiones confiables ya que, en general, las casas encuestadoras no presentan errores asociados a las estimaciones de cada candidato, sino un error cota o límite cuyo valor, aseguran, no es rebasado por los errores de las estimaciones de los candidatos. Los errores de Quadri y Otros Candidatos, deben ser bastante menores que los tres candidatos con mayor preferencia electoral.
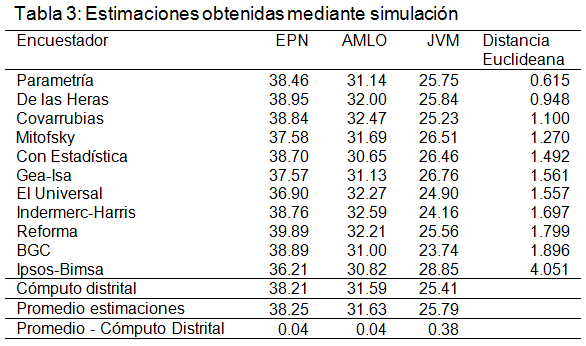
En la Tabla 3 se muestran las estimaciones generadas mediante simulación. Se observa que no hay valores repetidos para ningún candidato. Además, el promedio de las estimaciones de cada candidato está muy cercano al valor respectivo del Cómputo Distrital, debido a que el promedio de las estimaciones es un buen estimador del parámetro que se está estimando: el resultado del Cómputo Distrital.
En la Figura 3 se muestran graficadas las estimaciones de las casas encuestadoras, obtenidas mediante simulación y cuyos valores numéricos se muestran en la Tabla 3. Se muestra la simetría de las estimaciones respecto al valor que están estimando, es decir hay desviaciones positivas y negativas, prácticamente con la misma probabilidad; las desviaciones extremas se observan menos que las desviaciones cercanas. Además, el promedio de las estimaciones de cada candidato es muy cercano al resultado del cómputo distrital. El promedio de las estimaciones para López Obrador prácticamente coincide con el resultado del cómputo distrital, hay una diferencia de sólo 0.01 puntos porcentuales.
Se tiene que las estimaciones obtenidas mediante simulación si satisfacen los principios estadísticos que antes fueron postulados, mientras que las estimaciones de las casas encuestadoras mostradas en la Figura 2 no los cumplen, se “equivocan” y con mucho a favor del candidato que más gastó en la campaña electoral de 2012.
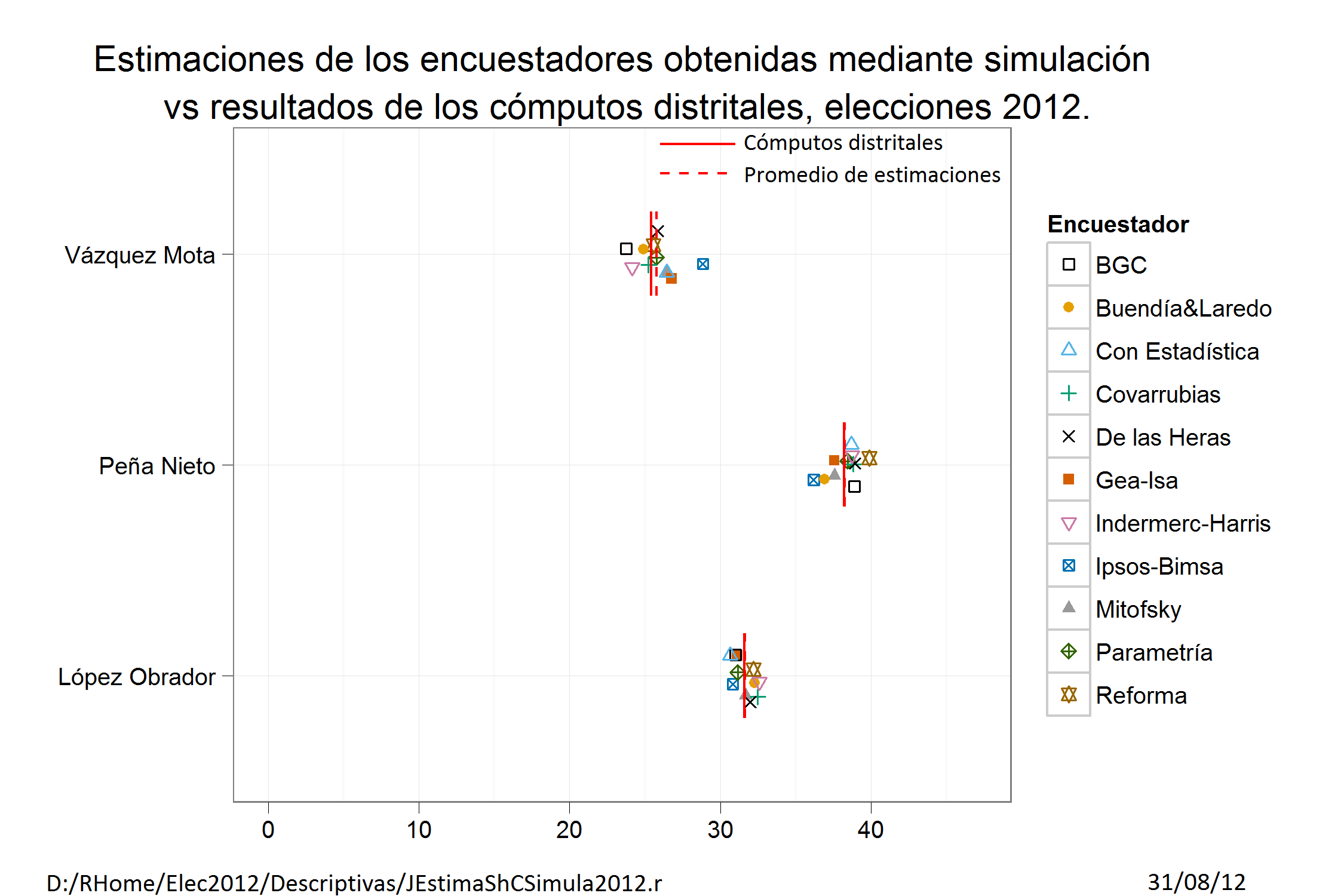
Figura 3
Intervalos de confianza de las estimaciones de las casas encuestadoras
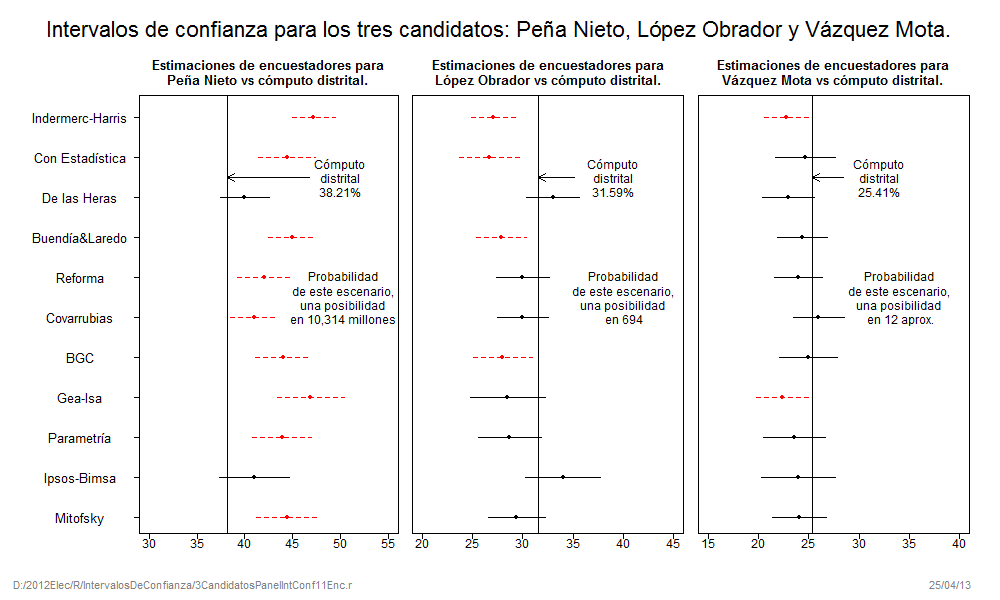
Figura 4
Como se puede observar de la figura anterior, la probabilidad de que solamente 3 de los 11 intervalos de confianza de las casas encuestadoras contengan el resultado del cómputo distrital –asumiendo que este es el resultado real- para Peña Nieto, es de 5.52605X10-9: una posibilidad en 180.96 millones. La probabilidad de que ocurra el escenario para López Obrador –sólo 5 de los 11 intervalos de confianza contengan el resultado del cómputo distrital–, es de 5.58573X10-6: una posibilidad en 179,027. La probabilidad de que ocurra el escenario de Vázquez Mota es de 0.01368: 1 posibilidad en 73. Como se puede observar, todas las estimaciones de los encuestadores tienen sesgo positivo para Peña Nieto; todas las estimaciones para López Obrador y Vázquez Mota, tienen sesgo negativo, con excepción de una sola estimación en cada caso.
Si se considera el escenario global, para los tres candidatos solamente 16 de los intervalos de confianza de los 33 contienen al valor respectivo del cómputo distrital, lo que indica que sólo el 16/33 = 0.4848, sólo el 48.88% de los intervalos de confianza de los encuestadores, contienen el resultado del cómputo distrital respectivo. Esto indica que los encuestadores trabajaron con un nivel de confianza observado del 48.88% -el porcentaje de intervalos de confianza que contienen el valor que estaban estimando- cuando estos afirmaron trabajar con el 95% de confianza. La probabilidad de que se presente este escenario global para los tres candidatos, en estimaciones legales u honestas, es: 3.91801X10-14. Un evento prácticamente imposible de ocurrir, por supuesto, con encuestadores honestos.
Viendo este conjunto de encuestadores como un sistema de medición, se tendría un sistema totalmente incapaz. Y más cuando se trata de encuestadores profesionales, algunos de los cuales tienen cerca de 25 años realizando encuestas, como es el caso de Ulises Beltrán, Roy Campos y Ricardo de la Peña.
En un artículo firmado por Tania Rosas y aparecido en el diario El Economista, titulado: Encuestador analiza denuncia contra AMLO[2], escribe:
Beltrán consideró que pese a las críticas de los partidos de izquierda a las encuestadoras, la credibilidad de estas empresas no está en crisis y destacó que todas las encuestas fueron precisas en cuanto a los lugares que ocupó cada uno de los candidatos a la Presidencia, aunque admitió que algunas tuvieron errores en cuanto a los puntajes.
No obstante, comentó que no le parece un error desmedido ni exagerado y precisó que las encuestas no son pronósticos, sólo miden las preferencias al momento.
Y añade:
¿Obligarnos a ser precisos?, pues no pierdan su tiempo. Éste es un método basado en principios de probabilidad y estadística que por su misma naturaleza tiene variación, tiene error y las restricciones legales las tenemos para publicar antes de la elección”, precisó.
Ulises Beltrán es un viejo lobo de mar y se defiende como puede; sin embargo, un punto clave es que el hecho de que el muestreo estadístico esté basado en principios de probabilidad y estadística, no justifica el que se den escenarios tan improbables, y algunas veces prácticamente imposibles, como los mostrados en la Figura 4.
Puesto que el método de muestreo estadístico está basado en principios de probabilidad y estadística, debe satisfacer algunos principios estadísticos, algunos de los cuales ya se mencionaron. Cuando se presentan escenarios tan improbables –el de Peña Nieto casi imposible- como el de los candidatos anteriores, pudiera deberse a que:
- Los encuestadores involucrados son unos incompetentes.
- Las estimaciones están manipuladas por los encuestadores, en cuyo caso se estaría ante una auténtica mafia o cártel de las casas encuestadoras.
La primera opción debe quedar descartada ya que éstos son encuestadores profesionales desde el punto de vista técnico, algunos de los cuales tienen casi 25 años haciendo encuestas.
La única opción viable es que las estimaciones de las casas encuestadoras estén manipuladas y, por lo tanto, muy probablemente hubo un acuerdo entre las mismas.
Un argumento usado en su defensa por algunos encuestadores es que un evento improbable o imposible puede ocurrir. Sin embargo, si se analizan las estimaciones de encuestas presidenciales anteriores, se verá que algunos escenarios planteados por éstos son, también, prácticamente imposibles de ocurrir, y el que estén ocurriendo en elección tras elección este tipo de escenarios en forma legal u honesta es imposible de suceder. Se estaría en un auténtico mundo al revés donde los escenarios improbables, o prácticamente imposibles, ocurren con mayor frecuencia que los probables.
Intervalos de confianza de las estimaciones obtenidas mediante simulación
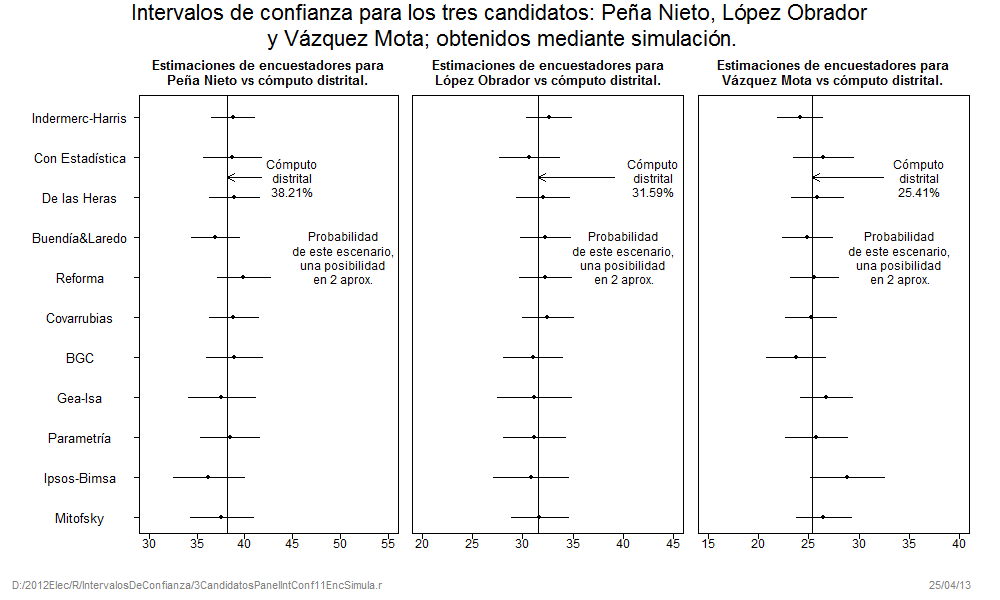
Figura 5
En la Figura 5, se muestran las estimaciones obtenidas mediante simulación para los tres principales candidatos –por su preferencia electoral- y asumiendo que las preferencias de los candidatos fueron los resultados oficiales del cómputo electoral, y su precisión fue la reportada por estas casas encuestadoras, y mostradas en la Tabla 2.
Como se puede apreciar de la Figura 5, las estimaciones de los tres candidatos son simétricas alrededor del resultado del cómputo distrital –el cual están estimando-, en el sentido de que, aproximadamente la mitad de estas son menores que el resultado del cómputo distrital respectivo, y la otra mitad son mayor. Se cumple también el principio de que es más probable obtener estimaciones cercanas al valor estimado –el resultado del cómputo distrital– que obtener estimaciones lejanas. Los dos anteriores principios derivados de que las estimaciones tienen una distribución normal, como antes se planteó.
En el escenario para Peña Nieto, con las estimaciones obtenidas mediante simulación; todos los intervalos de confianza contienen el valor asumido como real, el resultado del cómputo distrital. En tanto que para López Obrador y Vázquez Mota, ocurre el segundo escenario más probable, solamente uno de los intervalos de confianza, en cada caso, no contiene el valor asumido como real en la simulación, el valor del cómputo distrital para estos candidatos.
Conclusiones
- Hemos visto que las estimaciones obtenidas mediante encuestas probabilísticas satisfacen algunos principios estadísticos, derivados del hecho de que estas estimaciones se distribuyen en forma normal.
- Que las estimaciones de las casas encuestadoras en las elecciones del 2012 –sobre todo las mediáticas que se estuvieron difundiendo públicamente y, por lo tanto, tuvieron un impacto en la opinión pública-, no satisfacen los principios estadísticos que antes se ha señalado.
- Que las casas encuestadoras se equivocan en sus estimaciones, como los mismos encuestadores lo han reconocido, pero que, extrañamente, estas “equivocaciones” han sido a favor del candidato que más gastó en la campaña electoral; y estas mismas “equivocaciones” perjudicaron al resto de los candidatos, con excepción de Gabriel Quadri. Recordemos que en las elecciones de 2006, las “equivocaciones” de Gea-Isa a favor de Felipe Calderón, fueron premiadas con la dirección de Pemex para Jesús Reyes Heroles, y la dirección del Cisen para Guillermo Valdés Castellanos, ambos de la empresa GEA.
- Que los escenarios de las estimaciones de estas casas encuestadoras son demasiado improbables, o prácticamente imposibles de obtenerse con encuestadores profesionales y honestos.
- Que los patrocinadores de la mayor parte de las casas encuestadoras son medios de comunicación –parte de los poderes fácticos-, lo cual pudiera indicar que estas “equivocaciones” no lo fueron tanto, sino fue parte de un esquema orquestado.
Agradecimientos y Notas
Agradecimientos: Agradezco la revisión y observaciones hechas a este documento por: Daniel González Sepúlveda, Jesús Ibarra Salazar y Jorge Gómez Báez.
Notas: Para los gráficos de este texto se utilizó el software R, el cual es un lenguaje computacional similar al lenguaje S desarrollado en Bell Laboratories. El software R fue escrito inicialmente por Ross Ihaka y Robert Gentleman a mediados de la década de 1990. Desde 1997, el proyecto R ha sido organizado y por the R Core Team. R está siendo desarrollado para las familias de sistemas operativos Unix, Macintosh y Windows. R es un software de código abierto y es parte del proyecto GNU. La página de internet de R (http://www.r-project.org) contiene más información acerca de R e instrucciones para bajar una copia.
Se utilizó también el software ggplot2, el cual es un software que es uno de los tantos paquetes de R y desarrollado por Hadley Wickham. La página de ggplot2, mantenida por Hadley Wickham, se encuentra en la siguiente dirección: http://had.co.nz/ggplot2/
El programa para la simulación que se muestra en la Figura 1, es un programa basado en un programa de Yihui Xie, el cual tiene un sitio de internet en http://yihui.name/en/. Al programa original de Yihui Xie, le agregué un histograma y le hice algunas otras modificaciones cosméticas.
Referencias:
[1] Identificaremos a Error, Error Muestral y Precisión como el mismo concepto.
[2] El artículo de Tania Rosas se puede encontrar en: http://eleconomista.com.mx/sociedad/2012/07/30/encuestador-analiza-denuncia-contra-amlo

Por Miguel Ángel Vargas V. ADNPolítico @Marca_Personal
Agosto 31, 2012
El Tribunal Electoral del Poder Judicial de la Federación (TEPJF) exoneró a las agencias encuestadoras de haber manipulado los resultados de sus estudios como forma de propaganda a favor del candidato presidencial del PRI y PVEM, Enrique Peña Nieto.
Luego de que la coalición Movimiento Progresista acusó en su juicio de inconformidad que las encuestas electorales fueron utilizadas como medio de publicidad o presión a favor de la candidatura del priista, los siete magistrados electorales consideraron infundado el agravio.
El proyecto de sentencia, que fue aprobado por unanimidad en la sesión del TEPJF de este jueves, también consideró infundadas el resto de las acusaciones de la coalición que postuló a la Presidencia a Andrés Manuel López Obrador, por lo que rechazó su solicitud de invalidez de la elección.
El máximo tribunal electoral del país estimó inadecuado considerar que las mediciones de intención de voto sean equiparadas como predicciones de eventos futuros.
Los estudios demoscópicos, indicó, no son adecuados ni suficientes para aducir una influencia sobre el comportamiento final del electorado.
“Si bien los resultados publicados por las encuestas precisadas en la demanda no coincidieron con el resultado de la elección, lo cierto es que la (coalición) actora no destaca algún aspecto ni ofrece elemento probatorio alguno que permita advertir la presencia de algún error muestral o algún sesgo en la metodología de las encuestas”, justificó el ministro Salvador Olimpo Nava Gomar.
… Y DEFIENDEN A MILENIO-GEA/ISA
El juicio de inconformidad presentado por la coalición de izquierda acusó con mayor dureza a la encuesta de GEA-ISA, patrocinada por el diario Milenio, que fue la de mayor difusión porque tuvo una periodicidad diaria, y fue la que tuvo mediciones más alejadas del resultado electoral.
“Milenio Televisión y Diario ejercieron presión a los electores publicando todos los días supuestos resultados de encuestas (…) en el que permearon de manera permanente y sistemática que Enrique Peña Nieto irremediablemente seria (sic) electo presidente de los Estados Unidos Mexicanos”, señalaba el documento.
El texto también argumentaba que el admitir las fallas de las mediciones de Milenio-GEA/ISA implicaba que reconocieron “la falacia que encerraron”.
La magistrada María del Carmen Alanís Figueroa dijo, al defender el proyecto de sentencia, que la coalición demandante debió probar sus dichos del uso propagandístico de las encuestas, y no lo hizo.
“Afirmar sin probar que la difusión reiterada de las mismas es un ejercicio propagandístico a favor del candidato de una coalición y en perjuicio del otro, es confundir la naturaleza y los fines no sólo de la investigación de opinión pública, sino del ejercicio periodístico amparado en el más amplio derecho fundamental a la libertad de expresión”, explicó.
Sólo hay una salida: reponer la elección
Víctor M. Toledo
La Jornada, 10 de Agosto de 2012
La idea de que el uno por ciento explota, domina, depreda, expolia, abusa y/o somete, al restante 99 por ciento parece en principio descabellada. Suena igualmente como algo demasiado radical. Y, sin embargo, es una tesis empíricamente demostrable por medio de datos, estadísticas, encuestas, censos. El pensamiento crítico revela con datos duros la realidad lacerante del mundo y del país. Quien logra informarse, se sorprende, se irrita y se enciende. Ellos son los indignados, cuyo número crece cada día en todo el planeta, incluido México.
Desde hace unos 5 mil años, la historia de la especie humana es una cruenta batalla entre tres poderes, el político, el económico y el social, y entre éstos y la naturaleza. Como resultado del juego democrático, el mundo moderno debería, en teoría, marcar un justo equilibrio entre esos tres poderes. Y en teoría también la democracia, un invento soberbio, debería ser la institución que privilegie el control ciudadano sobre los otros dos poderes. La realidad lo contradice. A los antiguos despotismos, tiranías y dictaduras, les ha sucedido y sustituido una nueva forma de opresión. En abierta u oculta complicidad, los monopolios económicos y los políticos han convertido al planeta en un mundo injusto e inseguro, donde una minoría de minorías mantiene la sujeción social y atenta contra el equilibrio de la naturaleza. Este nuevo escenario envía a la bodega de desechos buena parte de las tesis clásicas o convencionales de la izquierda. El conflicto ya no es entre proletarios y patrones, pobres y ricos, marginados e incluidos, etcétera, sino entre el 99 por ciento y el puñado que los somete. Leer más…
